In this section
- Disclaimer and feedback
- Main points
- Things you need to know about this release
- Background
- Household statistics for 2011
- Household statistics for 2016
- Summary and next steps
- Feedback
- Annex 1: Dual system estimation calculations for number of occupied addresses in local authorities
- Annex 2: DSE performance measures
1. Disclaimer and feedback
The Research Outputs are NOT official statistics on the population. Rather they are published as outputs from research into an Administrative Data Census approach. These outputs must not be reproduced without this disclaimer and warning note, and should not be used for policy- or decision-making.
If you have any questions or feedback please email Admin.Data.Census.Project@ons.gov.uk (and include the subject line “Research Outputs feedback”).
Back to table of contents2. Main points
Following the publication of our Research Outputs on occupied address (household) estimates from administrative data: 2011 and 2015, we’ve investigated using a coverage survey to improve estimates for the number of occupied addresses in England and Wales by local authorities.
Using a dual system estimation (DSE) method, our 2011 coverage-adjusted estimate of 23.4 million occupied addresses is 0.29% higher than the 2011 Census estimate for the number of households in England and Wales.
This is an improvement on our previous unadjusted estimate of 22 million occupied addresses, which was 5.9% lower than the 2011 Census estimate for the number of households in England and Wales.
More detailed research needs to be undertaken to understand potential sources of bias in the DSE approach and to support development of a Population Coverage Survey (PCS) to adjust for coverage biases on administrative data for households.
This publication includes our first attempt at using administrative data to produce distributions of how households are made up for England and Wales and by local authorities; this initial research has produced encouraging results.
A framework for evaluating the quality of household composition estimates is yet to be developed; however, distributions for the majority of categories are comparable with 2011 Census estimates.
Following the publication of our Research Outputs on occupied address (household) estimates by size: 2011, we also include household size estimates for 2016, with comparisons with estimates from the Annual Population Survey (APS) at national level.
3. Things you need to know about this release
In this release, we use the term “households” when referring to the estimates that have been produced for these Research Outputs. These estimates are actually based on the concept of “occupied addresses” from administrative data, which is different from traditional “household” definitions used in censuses and surveys. The main aim of these outputs is to highlight what can currently be achieved using administrative data to meet the traditional definition of “household”.
For this release, we’ve attempted to identify and remove communal establishments by using address classifications on Ordnance Survey’s AddressBase1 product. This is more consistent with the definitions used in household statistics produced from the census and other social surveys. It may also explain some of the changes observed in the estimates published in this release compared with those published last year.
The administrative data Research Outputs presented in this release have been developed from the same population base used in our previous release – Statistical Population Dataset (SPD) Version (V)2.0. The SPD V2.0 is produced by anonymously linking records at person and address level from various administrative data sources. These include the NHS Patient Register (PR), the Department for Work and Pensions (DWP) Customer Information System (CIS), data from the Higher Education Statistics Agency (HESA) and England and Wales school census data.
Notes for Things you need to know about this release
- AddressBase – an Ordnance Survey address product compiled from local authority, Ordnance Survey and Royal Mail address lists.
4. Background
Detailed statistics about households are currently produced from the census every 10 years. In between census years, official household statistics are produced at national level using survey data that have an insufficient sample size to produce reliable small area household statistics. One of the advantages of a future Administrative Data Census is the potential to produce detailed household statistics on a regular basis for small geographies.
In our previous release Occupied address (household) estimates from administrative data: 2011 and 2015, we outlined a number of challenges associated with the use of administrative records in producing household statistics. These were summarised as the following.
Definitions of households
Address information in administrative data is generally collected from individuals registering for services, whereas surveys and censuses are designed to collect targeted information about households. This makes it challenging to meet the traditional definition of “household” using administrative data.
Address matching
As we’re using addresses as the basis for identifying and grouping individuals into households, our method depends on linking address information on administrative records to Ordnance Survey’s AddressBase product. While this enables us to standardise address information and use Unique Property Reference Numbers (UPRNs) to produce household statistics, approximately 4% of administrative records can’t be matched to a UPRN. Reasons for these non-matches are referred to in our previous release. Mostly, it’s due to the absence or insufficient quality of address information held in administrative sources.
Complex addresses
Some addresses require a UPRN hierarchy to identify where there are multiple dwellings within the same property. For example, purpose-built flats often have a “parent UPRN” for the entire building and “child UPRNs” for each flat within the building. In some situations, for example, in some student halls of residence, this hierarchy isn’t available and only the “parent UPRN” is identifiable as a single occupied address. For example, this means we might count one UPRN where we should be counting 30 child UPRNs.
Population exclusions
Currently we only include occupied addresses in our household statistics when there is evidence that they’re likely to be occupied by persons in the “usually resident”1 population. More information about our inclusion rules in the construction of Statistical Population Dataset (SPD) Version 2.0 are available in our Research Outputs on estimating population size using administrative data. In some instances, we may incorrectly determine that persons aren’t part of the usually resident population and consequently exclude the address they’re occupying from our household statistics.
The issues described in this section list only some of the challenges associated with using administrative records for household statistics. However, each of these were identified as a contributing factor in underestimating the number of occupied addresses when compared with the 2011 Census estimates.
One way of improving on these estimates is to make use of a coverage survey, similar to the methodology used in the 2001 and 2011 Censuses. Our unadjusted estimates for occupied addresses from administrative records in 2011 were 5.9% lower than the coverage-adjusted census estimate for the number of households. In this release, we outline how we’ve adapted the dual system estimation (DSE) census methodology to produce coverage-adjusted estimates for the number of occupied addresses. We also compare results with the 2011 Census estimates for numbers of households.
In addition to our research on coverage-adjusted outputs for 2011, we’ve also produced outputs for the number of occupied addresses for 2016. As suitable survey data aren’t currently available for the DSE approach described in the following sections, these estimates remain unadjusted but allow us to continue a time series of outputs for 2016. To supplement the time series for 2016, we are also releasing estimates of household size for 2016 using the same methodology reported in our previous publication, Occupied address (household) estimates by size, 2011.
This release also includes our first attempt at producing distributions of household composition. We present a methodology based predominantly on a rules-based approach for assigning household composition from information available on administrative records. This method is supported with an imputation approach for more complex households. We present analysis and outputs of household composition for both 2011 and 2016.
Notes for Background
- Usually resident population – we are currently adopting the UN definition of "usually resident" – that is, the place at which a person has lived continuously for at least 12 months, not including temporary absences for holidays or work assignments, or intends to live for at least 12 months (United Nations, 2008).
5. Household statistics for 2011
Using DSE to estimate number of occupied addresses
The basic capture-recapture approach of dual system estimation (DSE) is to count a sample of the population once and then count a second sample (most often in the form of a follow-up survey). DSE is traditionally used to account for under-coverage in the form of non-response and was used in the 2001 and 2011 Census coverage-adjustment process.
The statistical assumptions of DSE are:
- there is perfect matching between addresses on the Statistical Population Dataset (SPD) and survey using a high-quality unique identifier
- the address frame used is complete and of high quality -there are no erroneous records on the SPD or survey (see Coverage-adjusted administrative data population estimates for England and Wales, 2011 for explanation of “erroneous”)
- the SPD and survey, in this case, the Population Coverage Survey (PCS), are independent
As described in Occupied address (household) estimates from administrative data: 2011 and 2015, we’ve developed an automated methodology that links address records to AddressBase to assign Unique Property Reference Numbers (UPRNs). Only records that have been assigned to a UPRN via a successful match to AddressBase are included in the estimation and therefore we can assume a high quality of matching between addresses and the SPD.
AddressBase contains a list of residential addresses complied from local authority, Ordnance Survey and Royal Mail address information. Information about addresses is routinely updated on AddressBase and provides a comprehensive list of residential addresses in England and Wales. We intend to include an address check as part of our PCS test in summer 2018. This is to test our assumption that the coverage of addresses on AddressBase is accurate for estimating numbers of occupied addresses.
Erroneous records and their prevalence in administrative data was a particular focus in our recent Research Output on Coverage-adjusted population estimates, England and Wales, 2011. Here we describe in detail the issue of administrative data “over-coverage”. When using DSE to estimate the number of occupied addresses, over-coverage is only a problem if the addresses people have moved out of remain unoccupied. There are instances of vacant addresses appearing as occupied in administrative sources. However, this type of over-coverage will be less common than the over-coverage affecting the size of the population, where the individuals need to be registered in the right place. The type of over-coverage may affect the size of households, but it has little impact on the number of households.
The fourth assumption of DSE, which requires that the two sources used are collected independently, is arguably less of an issue when combining a coverage survey with administrative data in a DSE framework. This is because administrative data are collected independently by government departments and therefore non-registration is less likely to be indicative of non-response to coverage surveys. This assumption needs to be tested and we’re currently identifying suitable datasets and a framework for measuring dependence between survey response and administrative data registration.
Our Statistical Population Dataset (SPD Version (V)2.0), which is constructed by linking multiple administrative datasets, is used as the basis for the occupied address estimates we’ve produced in this Research Output. As mentioned in Section 4, we’ve used classifications on AddressBase to identify and remove communal establishments from SPD V2.0. Only records with UPRNs are included in the coverage-adjustment process.
Figure 1: Overview of the coverage adjustment methodology
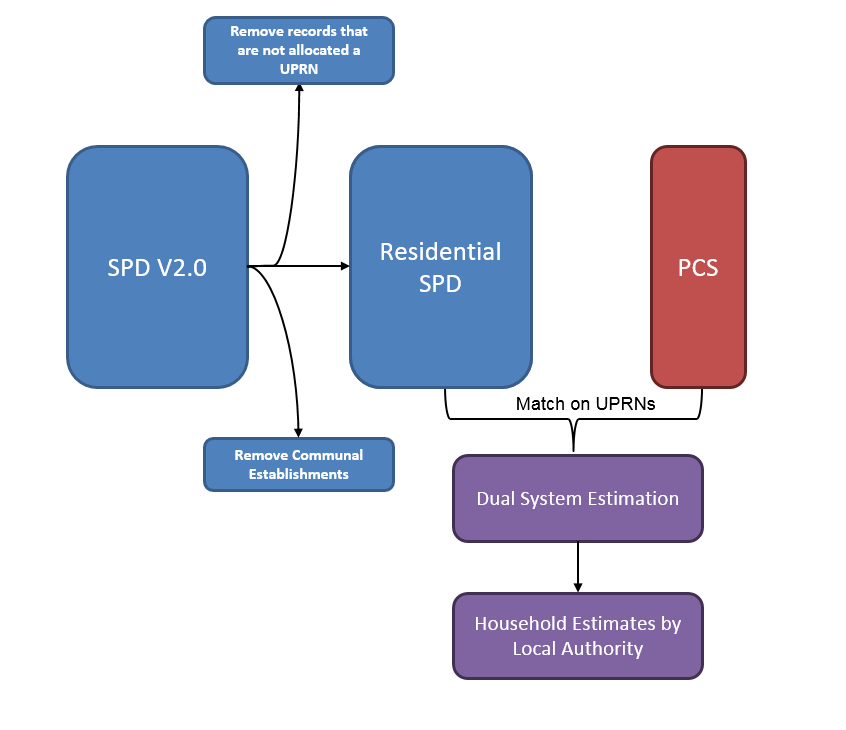
Source: Office for National Statistics
Download this image Figure 1: Overview of the coverage adjustment methodology
.PNG (38.5 kB)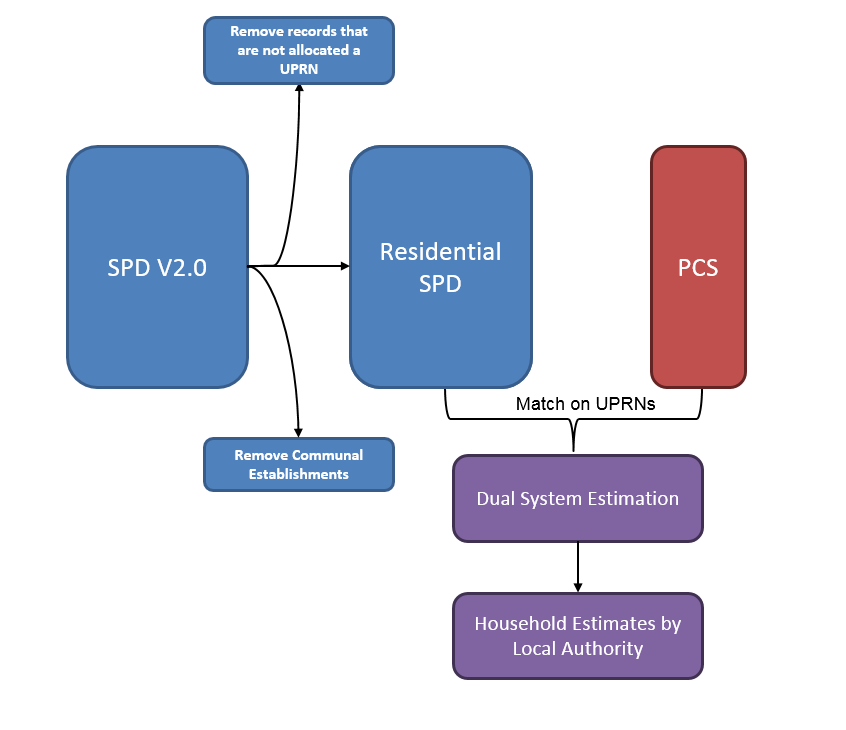{kind=link}
For coverage adjustment, we’ve sampled a Population Coverage Survey (PCS) using 2011 Census data, in a way that replicates the sample data that would typically be collected from a PCS in future (see Figure 2). This approach isn’t perfect and will be refined in future.
Our current method relies on creating a unique list of all Lower Layer Super Output Areas (LSOAs) in England and Wales, which we use as our Primary Sampling Unit (PSU) frame. We then randomly select 4% of these PSUs in every local authority and create a unique list of the Output Areas (OAs) within these LSOAs to form our Secondary Sampling Unit (SSU) frame. Our final sample is drawn by taking 25% of these SSUs to give us a 1% sample of OAs in England and Wales.
Figure 2: Overview of Population Coverage Survey sampling
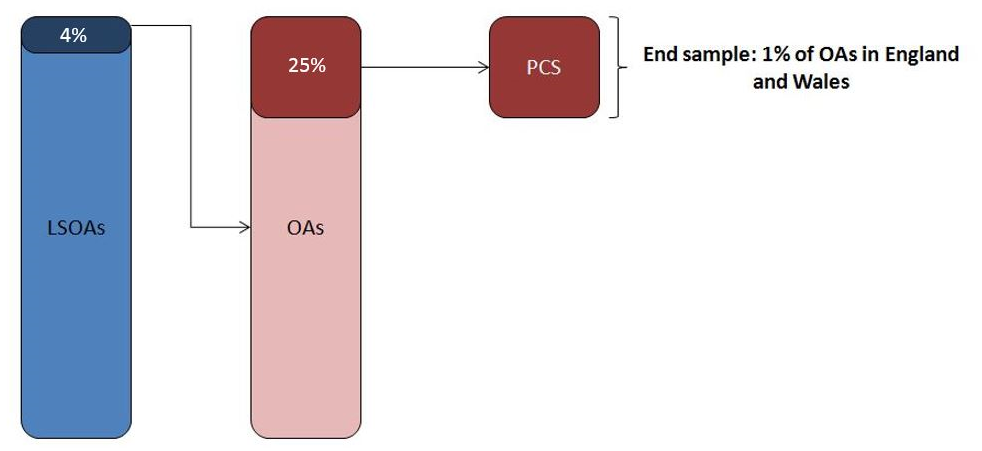
Source: Office for National Statistics
Download this image Figure 2: Overview of Population Coverage Survey sampling
.PNG (85.3 kB)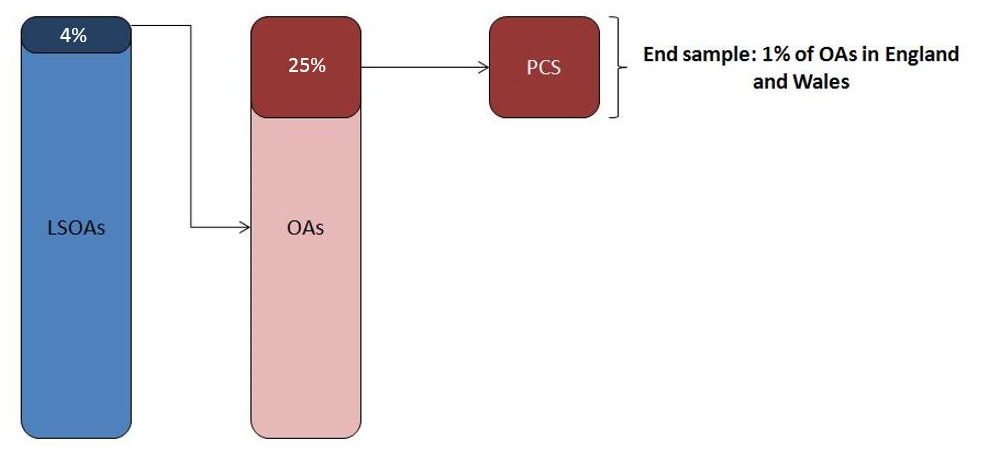{kind=link}
This approach ensures that the sample is spread across all local authorities in England and Wales and overall sample size is similar to what we expect to achieve in a future PCS. Figure 1 shows an overview of the methodology we use to produce our household estimates by local authority. For a more detailed description of how we have calculated DSE for occupied addresses at local authority level, please see Annex 1.
The method we’ve used is based on aggregating counts of occupied addresses across OAs that have been selected for the PCS within each local authority. By observing the number of occupied addresses that are counted in both the PCS and the SPD in the sampled areas, a dual system estimate is derived. This adjusts for occupied addresses that are missing from the SPD.
Within the sampled areas, the adjusted DSE total is compared with the unadjusted SPD total to derive a “ratio weight”. This is combined with the sample weight for each OA, which provides the basis for producing estimates for the number of occupied addresses in each local authority. See Annex 1 for a detailed description of this method.
To evaluate the quality of these estimates, a measure of variability is required. Since we are using 2011 Census data, repeated samples of data can be drawn using the process described previously to generate a PCS covering approximately 1% of England and Wales in each sample. In this study, we’ve repeated this process 100 times to obtain a distribution of estimates for each local authority on which to evaluate DSE performance.
Analysis of coverage-adjusted estimates
We use the following performance measures to assess the DSE for estimating the number of occupied addresses. These are:
relative bias (RB) – the percentage difference from the true population values; a small RB means that the estimate is close to our true population (official census household estimates)
relative standard error (RSE) – the mean variability of the estimates over the 100 simulations
relative root mean squared error (RRMSE) – a measure of the accuracy of the estimates, taking into account both RB and RSE; a lower RRMSE value means a more precise estimate
Performance at national level
The results from applying the dual system estimation (DSE) approach outlined previously are presented in Table 1. These results show that our coverage-adjusted estimate for the number of occupied addresses in England and Wales is approximately 68,000 (0.29%) higher than the 2011 Census estimate for the number of households. This is a vast improvement on the difference observed in our previous Research Output, where the unadjusted estimate for the number of occupied addresses was 1.4 million (5.9%) lower than the 2011 Census household estimates.
| Occupied address estimate | Difference from 2011 Census | |
|---|---|---|
| SPD V2.0 Unadjusted (Research Output, February 2017) | 21,980,124 | -1,385,920 |
| SPD V2.0 Coverage adjusted | 23,433,814 | 67,770 |
Download this table Table 1: National estimate and difference from census
.xls .csvTable 2 presents the results of the performance measures for the coverage-adjusted estimate at national level. The low relative bias of 0.29% is also accompanied with low measures of RSE and RRMSE of 0.26% and 0.39% respectively. However, we expect measures of variance to be lower at national level than at local authority level.
| Relative Bias (%) | RSE (%) | RRMSE (%) | |
|---|---|---|---|
| Coverage adjusted estimate | 0.29 | 0.26 | 0.39 |
Download this table Table 2: Performance measures of national estimate (with coverage adjustment)
.xls .csvPerformance at local authority level
At local authority level, the quality of our estimates varies. Figure 3 shows the proportion of local authorities with percentage point differences from the 2011 Census household estimates. Two distributions are plotted, the darker (blue) bars showing percentage differences for the unadjusted estimates of occupied addresses, lighter (yellow) bars for the DSE-adjusted estimates.
When the DSE adjustment is applied, a larger proportion of the 348 local authority estimates are closer to the 2011 Census household estimates. There are also far fewer local authorities in the lower tail of the distribution with occupied address estimates that are more than 10% lower than the 2011 Census household estimates.
Figure 3: Local authority distribution with difference from census
England and Wales, 2011
Source: Office for National Statistics
Download this chart Figure 3: Local authority distribution with difference from census
Image .csv .xlsWe don’t currently have any quality standards for estimating the number of occupied addresses. These will be developed in future. However, for now we can use the quality standards we’re currently using to evaluate the quality of population estimates.
| Unadjusted estimate for number of occupied addresses | DSE adjusted estimate for number of occupied addresses | |||
|---|---|---|---|---|
| Quality standard | Cumulative number of local authorities | Cumulative percentage (%) | Cumulative number of local authorities | Cumulative percentage (%) |
| P1: within ±3.8% | 109 | 31.3 | 336 | 96.6 |
| P3: within ±8.5% | 314 | 90.2 | 346 | 99.4 |
Download this table Table 3: Difference between adjusted and unadjusted estimates for the number of occupied addresses against quality standards
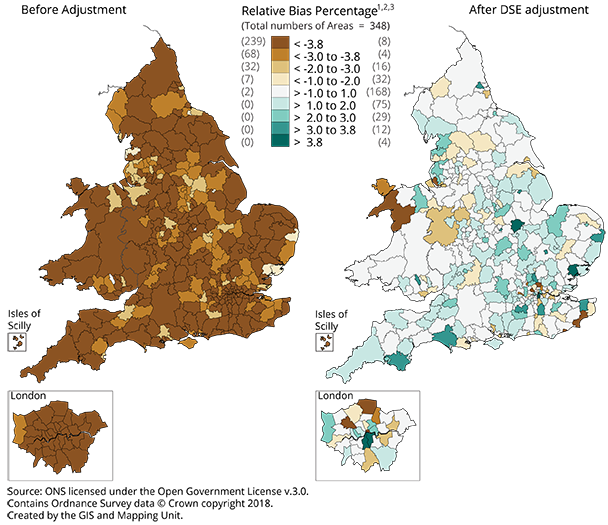
.xls .csvUsing the P1 and P3 quality standards, Table 3 shows that after the DSE adjustment has been applied, approximately 97% of local authorities fall within plus or minus 3.8% difference from census estimates and 99% within plus or minus 8.5%. This leaves only two local authorities with RB values outside 8.5%. These are City of London and Gwynedd.
When compared with our previous Research Output results, we see a vast improvement in meeting the quality standards, specifically P1 – an additional 227 local authorities (65%) now meet the P1 quality standard and fall within plus or minus 3.8% difference from census estimates. Because of this, when we map the adjusted results and compare with our previous results (see Figure 4), we use scales at a finer granularity from what we did in our previous Research Output.
Figure 4: Relative bias before and after the dual system estimation (DSE) coverage adjustment, England and Wales, local authority areas
Source: Office for National Statistics
Notes:
- Relative bias is the percentage difference between the Statistical Population Dataset and the 2011 Census.
- Dual System Estimation is the basic capture-recapture statistical approach to estimate the size of a population.
- These maps are not to be interpreted as standalone. Please see Section 5 in the Research Output: an update on developing household statistics for an Administrative Data Census, for more information.
Download this image Figure 4: Relative bias before and after the dual system estimation (DSE) coverage adjustment, England and Wales, local authority areas
.png (279.1 kB) .xlsx (22.3 kB)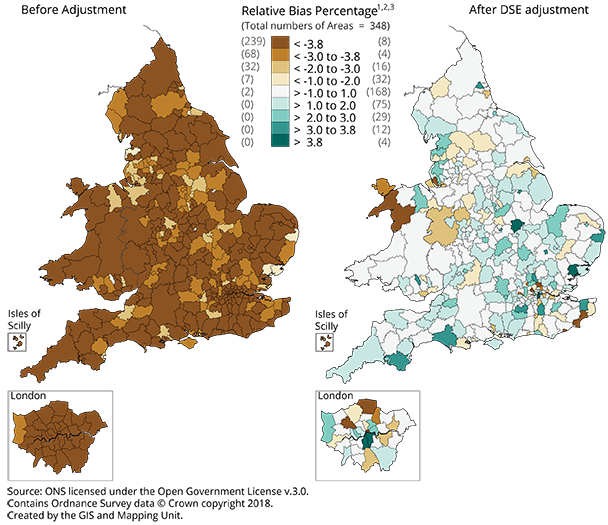{kind=link}
The map in Figure 4 with unadjusted estimates shows that we underestimated the number of households using occupied addresses by more than 4% for the majority of local authorities. For adjusted estimates, almost half of local authorities are within 1% difference from the 2011 Census household estimates (coloured in the lightest shade, grey). Some local authorities have slightly higher estimates, which may be the result of over-coverage as described in Section 4.
The most notable regional change after the application of DSE is in London. As Figure 4 shows, every local authority in London (apart from one) was undercounting census by more than 4% prior to the coverage adjustment. After the DSE adjustment, we now see a mix of over- and under-estimation in London.
Table 4 displays the 10 local authorities with the largest percentage difference from 2011 Census household estimates using the DSE adjustment. Six of the ten local authorities show a negative bias (underestimating compared with census) and four show a positive bias (overestimating compared with census). We can’t observe all possible sources of error in the DSE adjustment. More detailed simulation studies are needed to understand how different sources of bias impact on the DSE framework for producing estimates of occupied addresses.
| Rank | Local authority | Relative bias (%) |
|---|---|---|
| 1 | City of London | -23.7 |
| 2 | Gwynedd | -8.8 |
| 3 | Hastings | -6 |
| 4 | Southwark | 5.5 |
| 5 | Lambeth | 5.2 |
| 6 | Rutland | 5 |
| 7 | Liverpool | -4.7 |
| 8 | Isles of Scilly | -4.5 |
| 9 | Colchester | 4.2 |
| 10 | Shepway | -4.1 |
Download this table Table 4: 10 local authorities with the largest absolute relative bias (after coverage adjustment)
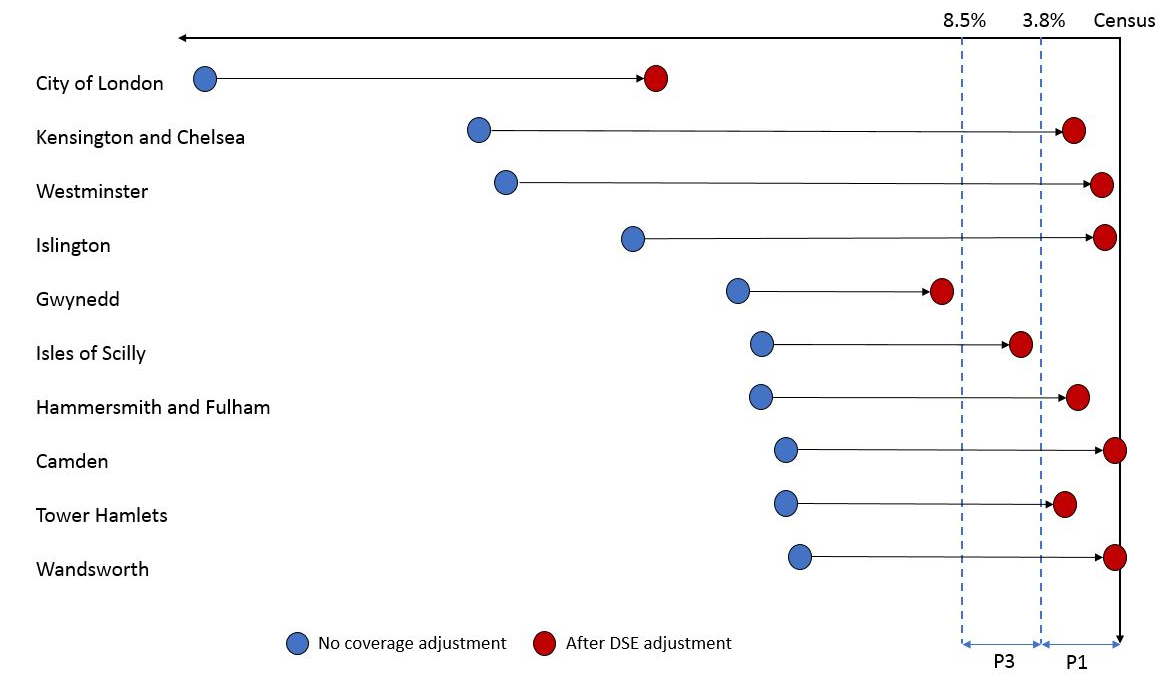
.xls .csvFigure 5 shows the 10 local authorities that had the largest percentage difference from 2011 Census household estimates in our February 2017 Research Output and the impact of our coverage adjustment. In all 10 local authorities, our estimates are closer to census after the DSE adjustment, although the magnitude of improvement varies by local authority.
Previously, all 10 of the local authorities were failing to meet the P3 quality standard (within plus or minus 8.5%.). After DSE is applied, seven of these now meet the P1 quality standard (within plus or minus 3.8%) and one meets the P3 quality standard (see Figure 5). The largest improvement is seen in Kensington and Chelsea with a move of 32 percentage points towards the official census estimate.
As mentioned previously, City of London and Gwynedd still don’t meet the P3 quality standard and both local authorities still undercount census. However, the estimates for these two local authorities considerably improve after the coverage adjustment, with improvements of 27 and 13 percentage points respectively.
Figure 5: 10 previous worst performing local authorities and the impact of the coverage adjustment
Source: Office for National Statistics
Download this image Figure 5: 10 previous worst performing local authorities and the impact of the coverage adjustment
.PNG (193.8 kB) .xlsx (11.2 kB)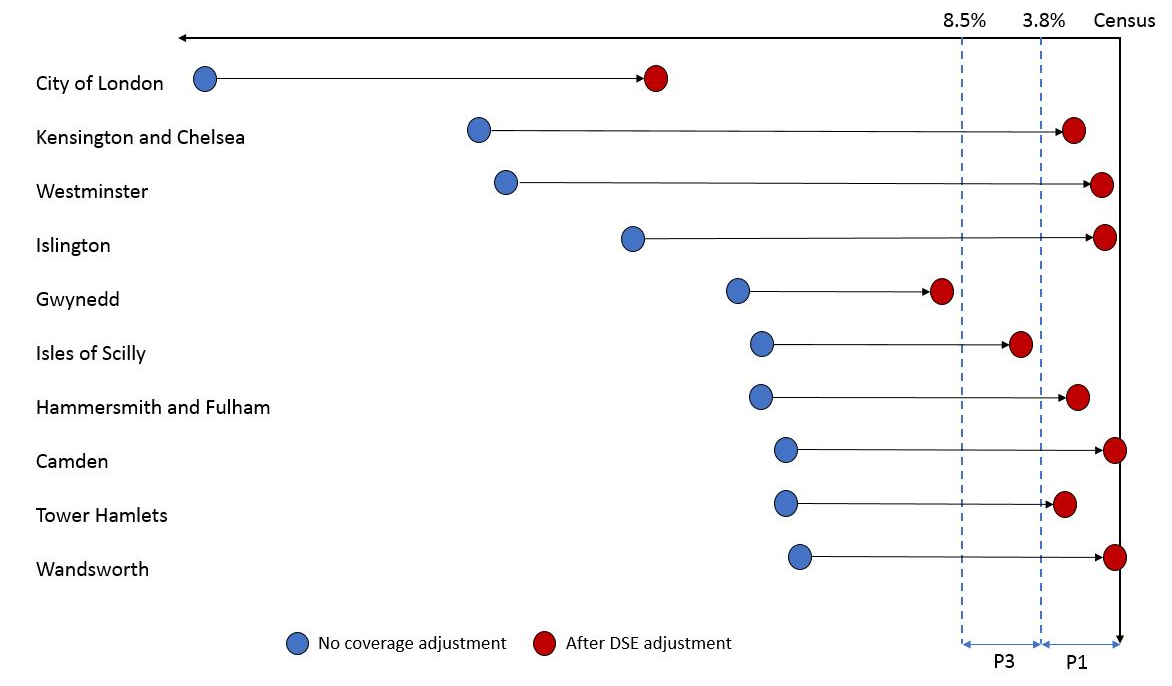{kind=link}
More detailed simulations are needed to understand potential sources of bias in these outputs. Occupied address estimates for the majority of local authority estimates are reasonably close to 2011 Census estimates. However, it’s possible that the effects of positive and negative sources of bias are cancelling each other out to produce estimates that are comparable with census. Potential sources of bias are listed in the following points and can’t be directly measured in this study:
matching error in the link between address on PCS and SPD to AddressBase – some addresses on the PCS and SPD can’t be successfully linked to AddressBase to assign UPRN; these addresses are subsequently excluded from the DSE, which is a negative source of bias
missing addresses from AddressBase – until we undertake an address check (intended for summer 2018), we have some uncertainty about the coverage of AddressBase; incomplete coverage would be a negative source of bias
violating the independence assumption – we haven’t yet tested whether there is a correlation between non-registration on administrative sources and non-response to surveys; if non-registration is predictive of lower survey response, this would also be a negative source of bias
over-coverage on administrative sources – as mentioned in Section 4, vacant addresses that appear occupied in administrative records would introduce a positive source of bias because residents have moved out and not updated their address records
When designing the future PCS, we’ll make use of detailed simulation studies to understand the impact of sources of bias on a DSE framework for producing household estimates from administrative data.
Summary of DSE research
This research is our first attempt at combining survey data with administrative data to produce coverage-adjusted estimates for the number of occupied addresses. In our previous publication, Occupied address (household) estimates from administrative data: 2011 and 2015, we discussed the potential need to replace the traditional census definition of “household” with an alternative that can be more accurately met with administrative data.
We’ve started to engage with users of household statistics in more detail to understand the impact that a change in definition would have. Discussions at our recent Royal Statistical Society (RSS) workshop1 on households and addresses identified that census household definitions have frequently changed to reflect how people live together. We also discussed the potential of moving towards approaches that have been successful in other register-based countries.
An alternative definition is likely to be needed, particularly when producing statistics about household composition and families. However, our research indicates that estimating the number of households might be achievable with an occupied address definition. This is further supported by our exploratory analysis of 2011 Census data, which indicates that the majority of UPRNs (99.6%) were occupied by a single household. However, there is still a need to estimate for houses in multiple occupation (HMOs); to do this we will consider how to make use of information that is collected about HMOs at local level.
We plan to use the findings of this research to inform the development of our PCS. In addition, we plan to use these coverage-adjusted estimates of the number of occupied addresses to adapt use of structure preserving estimator (SPREE) methods for producing household characteristic outputs. For example, we plan to use them to support the SPREE model to produce local authority estimates of household size.
Household composition
Background
While a PCS has considerable potential to improve estimates for the number of occupied addresses, producing statistics about the characteristics of households occupying addresses is more challenging with administrative data. Censuses and surveys can be designed to collect information about household members and their relationships, whereas administrative records tend to collect limited information about relationships between people living at the same address. Further complexities are also introduced when information is not up-to-date for all household members. Delays in registering change of address for example, can result in individuals being missed in household analysis, or people being incorrectly included in the same household.
More detail about the type of information we have available from administrative records can be found in our Household Composition SlideShare. In summary, we’ve combined relationship information from benefit claims with other information from across administrative sources, including pseudonymised surname comparisons and age-structures within addresses. We use this information to assign a 2011 Census household composition category to each UPRN on SPD V2.0.
Challenges associated with household composition from administrative data
In Section 4, we summarised several issues with using administrative data to produce household estimates. We’ve previously focused on how these may affect estimates of the numbers of households, but they may also affect the apparent composition of households. Even if households are correctly counted, the people assigned to a particular UPRN may not correctly represent a real household, in particular due to the following reasons.
Complex addresses
In cases where the parent UPRN is assigned instead of the child, the effect will be to make multiple households appear as a single larger, more complex household. This will lead to lower estimates of the simpler household types, which include only one person or one family and increase estimates of other types.
Incorrect population exclusions and inclusions
A household grouping may be misrepresented due to SPD V2.0 erroneously including or excluding people. For example, SPD V2.0 shows a substantial level of over-coverage for working age males when compared with the census and under-coverage for most other groups. This will modify the apparent structure of families and households in the SPD, producing biases in the resulting distribution of household composition categories.
Delays in updating administrative records
Another effect present in administrative data is lags caused by delays in updating the data after changes, such as when people move to a new address. If one or more people move out of an address, their records may still appear at the address in the data, even if the current occupants are also assigned there. This can also create artificially large households in the administrative data that can skew the distribution of household composition types.
Relationships in administrative data
ONS currently has access to tax and benefits data from the Department for Work and Pensions (DWP), some of which contain information on relationships collected for the purpose of administering benefits.
The National Benefits Database (NBD) contains information on claims for 13 different benefits. Of these, only the state retirement pension records show the identity of a claimant’s partner. State Pension claimants account for the majority of people on the NBD, but clearly this is limited to the older part of the population. ONS also has access to a separate dataset containing Housing Benefit claims, for which the partner identifier is collected for certain records. This dataset includes adults covering a broad range of ages, but a much lower proportion of the population is covered.
The other main type of relationship in determining types of families and households is the parent-child relationship. ONS now has access to the Child Benefit dataset, which shows the identifier for one of the parents.
This benefit has historically been claimed for the vast majority of children of eligible age, although recent changes introducing means-testing in 2013 may reduce coverage in later years. Since the change, payments are effectively reduced for parents with individual taxable income over £50,000 per year and effectively withdrawn for those with taxable income over £60,000 per year. This may lead to parents opting out and their children no longer appearing in the data.
Aside from the income criteria, children aged less than 16 years are eligible for a claim, as well as those aged between 16 and 19 years who are in approved education or training. The dataset includes claims ending in January 2009 as the earliest records, with the latest records being claims active in the tax year ending 2016. Therefore, in addition to current claimants, historical claims can be used to provide relationships that can also be used if the parent and child still live together but are no longer claiming. The cumulative nature of the dataset means that more parent-child relationships are available for use in later years.
Methodology overview
The current method we’ve developed relies primarily on a “rules-based” approach, which is based on a set of simple assumptions for household composition to UPRNs on SPD V2.0. These rules are applied in more straightforward situations, where the evidence available from administrative records provides a clear indication of the most likely type of household that is living in the address.
Deterministic rules method
The deterministic rules method attempts to allocate each household to one of the following broad household type categories:
- One-person household
- All-student household
- One-family household: lone parent
- One-family household: couple
- Other type of household
This roughly follows an order of complexity, with the simpler types allocated first and removed from consideration for the later categories. Any remaining households that haven’t been allocated to a category by the rules will then be handled using more sophisticated methods.
In order to define the two one-family household categories, it is necessary to define what is meant by a “family”. Since we’re aiming to replicate census categories, the census definition of a family is followed as closely as possible. The complete definition can be found in our Household Composition SlideShare. In summary, a family in the census definition is a nuclear family, which (apart from a few rare exceptions) contains only a couple or lone parent together with any children they have. Therefore, a household containing any extended family members is grouped into two separate families by the census household composition algorithm.
To qualify for either of the one-family household categories, a household must contain only a family of the given type, with no other people in the household.
One-person households
A one-person household is very simple to identify. If a single person on SPD V2.0 is found to registered at a UPRN, that address is allocated as a one-person household.
All-student households
Data from the Higher Education Statistics Agency (HESA) is used in construction of SPD V2.0 to identify students and to allocate their term-time location as their place of usual residence. If all people assigned to a particular UPRN were assigned to that area1 using HESA data, the household is identified as an all-student household.
One-family household: lone parent
This is the simplest type of one-family household to categorise, since only one type of relationship needs to be identified. The oldest person in the household must be the parent of all others. Parent-child relationships can often be identified using the Child Benefit data and an alternative rule to identify likely other relationships of this type has also been developed. These rules are shown in Figure 6. More detail about the coverage of Child Benefit data and an analysis of age distributions amongst parents and children, is available in our Household Composition SlideShare.
Figure 6: Rules to identify parent-child relationships

Source: Office for National Statistics
Download this image Figure 6: Rules to identify parent-child relationships
.PNG (41.2 kB) .docx (13.3 kB){kind=link}
One-family household: couple
This type of household contains a couple relationship between the oldest two people and all other people are children of either member of the couple. The Housing Benefit and State Pension data identify partner relationships only for a minority of potential couples, so most couple relationships are assigned using an alternative rule that finds plausible couples based on the age difference between the two people. These rules are shown in Figure 7.
If the oldest two household members meet either of these criteria, then all other people must be children of either member of the couple, with parent-child relationships fulfilling the criteria in Figure 6. More detail about the coverage of benefit claims between partners and an analysis of age distributions amongst couples is available in our Household Composition SlideShare.
Figure 7: Rules to identify couples

Source: Office for National Statistics
Download this image Figure 7: Rules to identify couples
.PNG (23.9 kB) .docx (13.2 kB){kind=link}
Other types of household
This category includes more complex households, which don’t contain only one person or a single family. It isn’t possible to design rules to identify all households in this category, but rules have been developed for two particular types, see Figure 8. More detail on these is available in our Household Composition SlideShare.
Figure 8: Rules to identify other household types

Source: Office for National Statistics
Download this image Figure 8: Rules to identify other household types
.PNG (33.4 kB) .docx (13.3 kB){kind=link}
Households not assigned by the rules
After applying the deterministic rules, approximately 91% of households are assigned to one of the five broad categories. The remaining 9% of households will either be:
couple-family households with an age difference between the couple of greater than 12 years
lone-parent and couple-family households with children where at least one parent-child relationship doesn’t satisfy the criteria in Figure 6
other household types that haven’t been identified by the rules in Figure 8
One of the limitations of a rules-based approach is that relationships between household members are only inferred when they are typical of the general population. For example, couples that have age differences of more than 12 years, or parents that have children past the age of 50 need to be included in the distribution. To take account for this variation, a probabilistic approach is needed to estimate the number of these households exhibiting these characteristics. One approach we’ve researched for doing this is based on assigning a composition to residual households by imputing from data collected from the 2015 Annual Population Survey (APS). More detail on the imputation method is available in our Household Composition SlideShare.
In summary, couple relationships are imputed by identifying “donor pools” of households in the APS that have a close match in the characteristics of adult residents on administrative records. One of the matched donor records can then be sampled at random from the APS. If the sampled donor record represents a couple relationship, then a couple relationship is imputed in the administrative record for which it has been selected as a match.
Following imputation, the data are rerun through the rules used to assign couple family households. The final part of the algorithm then reruns the lone parent and couple family rules several times, progressively modifying the criteria on parent-child relationships so they are less stringent. More detail on the full algorithm is available in our Household Composition SlideShare.
These steps each add a small percentage of records to the couple-family and lone-parent-family household categories. All remaining households that are not allocated a type at this stage are then assigned to the “other” category.
Comparisons with 2011 Census household composition
Detailed analysis of our comparisons between administrative data household compositions and the 2011 Census can be found in our Household Composition SlideShare accompanying this report. Figure 9 shows the overall results for England and Wales in 2011 for each of the five broad categories, compared with the equivalent 2011 Census categories. These are shown as percentages of households in each of the categories, since the overall numbers of households are lower than in the census.
Figure 9: Household composition broad categories
England and Wales, 2011
Source: Office for National Statistics
Download this chart Figure 9: Household composition broad categories
Image .csv .xlsThe distribution of household types appears broadly similar to the census equivalent. The administrative data method shows a smaller proportion of couple family households than the census, whilst showing more lone parent and “other” types of households. Since this is the first attempt to replicate this output and the methodology is relatively simple at this stage, there is potential to develop methods further to reduce the differences from census estimates.
Due to delays in individuals updating their addresses on administrative records, there is always a risk that couples will not be registered as living at the same address. Currently we have an excess of “other” household type and methods need to be developed to adjust for this.
More detailed household breakdown results for England and Wales
The census outputs also include more detailed household types. These include subcategories for households that contain only pensioners and “other” households are broken down by the dependency status of any children.
A child is defined as dependent if aged between 0 and 15 years, or aged 16 to 18 years and in full-time education. The Child Benefit data assist with determining the status of children aged between 16 and 18, since they must be in education to be eligible. Therefore, children in this age range with an active Child Benefit claim in March 2011 are considered to be dependent.
This additional information is used to produce the detailed categories shown in Figure 10.
Figure 10: Household composition detailed categories
England and Wales, 2011
Source: Office for National Statistics
Download this chart Figure 10: Household composition detailed categories
Image .csv .xlsSimilarly to the broad household type categories, the distribution of detailed categories is broadly similar to the equivalent census percentages. The largest difference is for couple-family households with no children. As these are two-person households by definition, much of this may be due to the smaller percentage of two-person households seen in the administrative data. Differences are also seen for lone-parent and couple-family households with children, where it appears that households with only non-dependent children are overestimated.
The difference seen in the “other” households category in Figure 10 appears to be due to households containing dependent children. This may be caused by lags in the administrative data, with people still registered at previous addresses. An extra person incorrectly included in a household containing a family will lead to classification in the “other” category rather than correctly as a couple- or lone-parent household.
Results for local authorities
Also contained in the Household Composition SlideShare is a map showing the relative performance of the method for the different local authorities.
The method performs relatively well in large areas of northern England and the Midlands, but relatively poorly in the South East. Areas containing large armed forces populations also stand out as comparing poorly with the census. This occurs because armed forces personnel are missing from the data that are used to produce household composition estimates. This leads to local authorities such as Richmondshire (see Household Composition SlideShare) showing a lower than expected percentage of couple-family households and higher percentages of lone-parent and one-person households. The correct inclusion of the armed forces personnel would change substantial numbers of these into couple-households, bringing the household composition distribution much closer to the census results.
Several areas of the South East perform less well than other regions in England and Wales. It is notable that the household size distributions for these areas also compare relatively poorly to census results and this is likely a significant influence on the household composition results. It is also notable that in the household size Research Output, the application of the structure preserving estimator (SPREE) method largely corrected the differences in these areas, with some among the closest results to census after the application of SPREE. We anticipate that applying the SPREE method to household composition categories could also make improvements in areas where our estimates are less comparable in future.
Summary of household composition research
This research is the first attempt by the Administrative Data Census to produce household composition statistics similar to the 2011 Census. The methods are relatively simple at this stage, with a large proportion of records handled by simple deterministic rules. The current results are encouraging, however and show an approximate agreement with the distribution of household types seen in the 2011 Census.
There are many potential sources of error that will lead to differences from census estimates when using administrative data for these purposes. These errors may arise either due to the household composition method itself, or due to coverage errors in the administrative data. To improve the method, it will be necessary to thoroughly evaluate the data and methods at each stage, finding the largest sources of error and improving the methods to correct for them. Record-level comparison with census data, or running the methods on census records themselves, will help to separate the effects of the method from those due to errors in administrative data.
We’ll continue to explore potential data sources with information on households and families, and consider how they might be incorporated into our methods. Of particular interest is information that can help identify a couple’s status as married or co-habiting. We intend to explore the use of birth registrations to improve the assignment of parent-child relationships. We also acknowledge that there may be changes in the quality and accessibility of existing information over time. For example, the impacts of future changes from the current benefits system to Universal Credit and the associated data collected about relationships between family members remain uncertain.
Notes for Household statistics for 2011
- The HESA data held by ONS do not contain full addresses, so HESA data alone cannot be used to allocate students to UPRNs, only to output areas. To assign a UPRN for a student it is necessary to find another source (either PR or CIS) which shows them in the same output area and assign them to the UPRN shown on that source. In many cases this is not possible, leading to all-student households being underestimated in the results.
6. Household statistics for 2016
Section 5 has demonstrated potential approaches for combining survey data with administrative records to produce household statistics. Most of our methodological development has been aimed at producing estimates for 2011, since comparison with 2011 Census estimates provides a good basis for evaluating the quality of our estimates and we can use the census data to simulate a Population Coverage Survey (PCS).
As part of this release, we’ve also produced estimates for 2016 to demonstrate our ability to produce annual household statistics for small areas using administrative data. In the absence of census data in 2016, we compare our estimates with household statistics produced from the Annual Population Survey (APS), which are produced at regional and national level.
Estimates for the number of occupied addresses, 2016
For our 2016 outputs, we don’t have timely census data from which we can draw a PCS sample in the same way as we did for our DSE approach with 2011 data. In future releases, we’ll aim to make use of PCS test data that we intend to collect for producing estimates of population size and number of households.
In the meantime, our 2016 estimate for the number of occupied addresses is based on unadjusted estimates using the same method reported in our previous Research Output Occupied address (household) estimates from administrative data: 2011 and 2015. Output datasets with 2016 estimates of occupied addresses down to local authority level accompany this release.
Figure 11 shows the percentage difference between our unadjusted estimates for the number of occupied addresses and Labour Force Survey (LFS) household estimates, for years 2015 and 2016. It shows that at a national level (England and Wales) our estimates are slightly closer to the LFS estimates in 2016 (negative 3.6%) compared with our 2015 estimates (negative 3.8%).
Figure 11: Percentage differences, Statistical Population Dataset version 2.0 with Labour Force Survey, 2015 and 2016
Government Office Regions, England and Wales, 2016
Source: Office for National Statistics
Download this chart Figure 11: Percentage differences, Statistical Population Dataset version 2.0 with Labour Force Survey, 2015 and 2016
Image .csv .xlsAt regional level, we see that 5 out of 10 regions have a smaller percentage difference in our 2016 estimates compared with our 2015 outputs. London estimates are more comparable in 2016, with a negative 4.9% difference in 2016 compared with negative 7.1% in 2015, as are Wales estimates with a negative 5.5% difference in 2016 compared with negative 7.1% in 2015.
Two regions have notably larger differences when comparing unadjusted occupied address estimates with LFS households in 2016. Yorkshire and The Humber has the largest change, with a difference of negative 5.4% in 2016 compared with negative 3.3% in 2015 and the North East has a difference of negative 6.3% in 2016 compared with negative 4.7% in 2015.
These differences at regional level could reflect changes in the coverage of addresses on AddressBase, or our ability to link addresses on administrative records to AddressBase.
Estimates of household size, 2016
In this release, we provide an update to the previous Research Outputs: Occupied address (household) estimates by size, 2011. Using the same methodology, we’ve derived household sizes for England and Wales, for 2016. Research Output datasets for household size distributions at local authority level accompany this report.
We’ve used a structure preserving estimator (SPREE) method to combine the Annual Population Survey (APS) with the administrative data, as we did for 2011 estimates. The percentage estimates from the SPREE method are available for download. For an explanation of how the SPREE method is applied to household sizes, see Research Outputs: Occupied address (household) estimates by size, 2011. The national distributions for household size are shown in Figure 12.
Figure 12: Percentages of household sizes
England and Wales, 2016
Source: Office for National Statistics
Download this chart Figure 12: Percentages of household sizes
Image .csv .xlsFrom the APS estimates (see Figure 12), we can see that nationally, one- and two-person households decrease between 2011 and 2016. Conversely, the larger household sizes increase, by up to 0.7 percentage points (three-person households). The SPREE method uses the APS distribution of household sizes, to adjust the Statistical Population Dataset (SPD) Version (V)2.0. For 2016, the SPD distributions are compared with the APS ones, as shown in Table 5.
| 1 | 2 | 3 | 4 | 5 plus | |
|---|---|---|---|---|---|
| SPD | 29.9 | 31.4 | 17.2 | 13.1 | 8.4 |
| APS | 27.2 | 35 | 16.8 | 14.2 | 6.8 |
| Difference | -2.7 | 3.6 | -0.4 | 1.1 | -1.6 |
Download this table Table 5: Percentage of household sizes, England and Wales, 2016
.xls .csvIn applying the SPREE method, which uses this national distribution as a marginal in the model (see Table 5), the national trend is reflected throughout local authorities.
Figure 13: Statistical Population Dataset versus Structure Preserving Estimator estimates
England and Wales, 2016
Source: Office for National Statistics
Download this chart Figure 13: Statistical Population Dataset versus Structure Preserving Estimator estimates
Image .csv .xlsWhen the SPREE method is applied to SPD estimates, the changes are shown in Figure 13. The percentages of households with one, three and five and over people all decrease and households with two or four people increase. The biggest effect of the SPREE method is to the percentage of two-person households at 3.6%. All local authorities increase or decrease by the same amount of percentage points and, as a result, no local authority household size distribution remains the same. Additionally, the rankings of percentages also remain the same, that is, those local authorities with the largest percentages of one-person households remain the largest after the SPREE adjustment.
It is difficult to assess the quality of these 2016 estimates, as we don’t have independent results, such as a census, to compare them with. We can, however, compare with our previous household size estimates for 2011. Figure 14 shows the comparison between our 2011 and 2016 SPREE household size estimates for England and Wales. We see a decrease in the proportion of one- and two-person households, whereas the proportion of households containing three or more people increases between 2011 and 2016. This national change can also be seen at regional level. The largest differences are seen in London on one- (negative 1.7 percentage points), two- (negative 0.8 percentage points) and four-person (1.1 percentage points) households.
Figure 14: Comparison of 2011 and 2016 Structure Preserving Estimator estimates
England and Wales, 2011 and 2016
Source: Office for National Statistics
Download this chart Figure 14: Comparison of 2011 and 2016 Structure Preserving Estimator estimates
Image .csv .xlsThese results are unsurprising when we analyse the difference between 2011 and 2016 APS data, which is what we use to adjust the SPD in the SPREE model. Figure 15 shows the percentage point difference in the proportion of each household size between the two years. As with the difference in our SPREE estimates (see Figure 15) we see proportions of one- and two-person households decreasing and proportions of households with three or more people increasing.
Figure 15: National trend in household sizes from Annual Population Survey
England and Wales, 2011 and 2016
Source: Office for National Statistics
Download this chart Figure 15: National trend in household sizes from Annual Population Survey
Image .csv .xlsThis release demonstrates the possibility of an annually-updated time series of outputs. As previously outlined, we plan to provide a time series from 2011 onwards for household sizes, with the exception of 2012, which we don’t have an SPD for.
The next steps for newest available year household size estimates would be to use a secondary survey to apply coverage adjustment to the local authority numbers, as we have trialled with 2011 estimates. Further refinement can also be applied to the SPD household base, such as the removal of communal establishment and possible short-term residents.
Household composition, 2016
The household composition methodology described in Section 5 has also been applied to SPD V2.0 in 2016. It is worth noting that a change to the eligibility rules for Child Benefit may have an impact on the 2016 results, with Child Benefit effectively no longer being paid to parents with incomes above £60,000 per year. As a consequence, we anticipate that a smaller proportion of dependent children appear on the dataset from 2013 onwards. Further research is necessary to fully evaluate the effect of this change on the household composition results and what impact it may have in future.
Research Output datasets for 2016 household composition distributions at local authority level accompany this release.
Although the method is still new and not completely accurate, it provides a basis from which small area household composition distributions can be produced. The current system doesn’t provide this for non-census years.
Figure 16 shows a comparison for the broad household composition categories between 2011 and 2016.
Figure 16: Household composition broad categories
England and Wales, 2011 and 2016
Source: Office for National Statistics
Download this chart Figure 16: Household composition broad categories
Image .csv .xlsThe chart shows that there is high consistency between the broad categories over time, with only small changes occurring. The percentage of couple-family households is slightly lower in 2016, with corresponding increases in the other household types and lone-parent categories.
The comparison for the detailed categories is shown in Figure 17.
Figure 17: Household composition detailed categories
England and Wales, 2011 and 2016
Source: Office for National Statistics
Download this chart Figure 17: Household composition detailed categories
Image .csv .xlsThe detailed categories show that the largest change is a decrease for couple-households with no children. However, households containing only a couple will move to the “One family only: all aged 65 and over” category when both partners reach age 65. The corresponding increase in this category suggests that these changes may be largely due to an ageing population in which pensioner couples comprise a greater proportion in 2016.
Only small changes with no consistent direction are seen for household types that contain dependent children, so the results don’t appear to show effects due to the changes to Child Benefit eligibility.
Comparison with social survey estimates
As previously mentioned, between census years, UK-level estimates of household composition are produced by ONS using social surveys. The sample sizes of these surveys are also sufficient to produce accurate estimates for England and Wales, but not at lower geographical levels. Figure 18 shows a comparison of the administrative data results to the 2016 Annual Population Survey (APS) estimates using closely comparable categories. The APS results show much higher percentages of couple-households with no children and couple-households with dependent children. Correspondingly, the APS estimates for “other” households are much lower.
The APS estimates also show high consistency over time, however, with the largest changing category between 2011 and 2016 being “One-person household: other”, which saw a decrease of about 1.4 percentage points. Therefore, the difference between the administrative data and APS estimates is also approximately consistent over time. For 2011, in the categories with large differences, the census estimates lie between the administrative data and APS estimates.
Figure 18: Comparison between administrative data and Annual Population Survey estimates
England and Wales, 2016
Source: Office for National Statistics
Download this chart Figure 18: Comparison between administrative data and Annual Population Survey estimates
Image .csv .xlsThe high level of consistency between the 2011 and 2016 results suggests that the method is stable and can be used to produce an annual time series of results. We need to observe whether the results remain stable by reproducing these estimates for other years. This includes the possibility of producing subnational estimates, which current methods using surveys can’t produce with sufficient precision.
It is currently not clear whether the administrative data method is detecting real changes over time, or if the changes seen are due to the level of uncertainty in the method. The method will now be evaluated with an aim to understand the level of accuracy and produce improvements. We’ll also share this approach with users to further understand if the results we see are consistent with local knowledge.
The allocation of person records to addresses has improved between 2011 and 2016, allowing the household type to be estimated for a greater proportion of households. Further improvements such as this to the earlier processes will have knock-on effects on the household composition results, likely improving the accuracy over subsequent years.
Back to table of contents7. Summary and next steps
8. Feedback
We’re keen to get feedback on these Research Outputs and the methodology used to produce them, including how they might be improved and potential uses of the data. Please email your feedback to Admin.Data.Census.Project@ons.gov.uk. Don’t forget to include the title of the output in your response.
Back to table of contents10. Annex 2: DSE performance measures
The equations for these performance measures are defined in this annex, where j is the simulation number and n the total number of simulations.