1. Disclaimer
These Research Outputs are NOT official statistics on the number of households in England and Wales. Rather they are published merely as outputs from research into a different methodology to that currently used in the production of household statistics.
It’s important the information and research presented is read alongside the outputs to aid interpretation and avoid misunderstanding. These outputs must not be reproduced without this disclaimer and warning note.
Back to table of contents2. Things you need to know about this release
In this report we use the term “households” when referring to the estimates that have been produced for these Research Outputs. These estimates are actually based on the concept of “occupied addresses” from administrative data, which is different from traditional “household” definitions used in censuses and surveys. The main aim of these outputs is to highlight what can currently be achieved using administrative data to meet the traditional definition of “household”.
The “household” estimates produced for these Research Outputs also include communal establishments (CEs). CEs aren’t included in household estimates produced from censuses and surveys and our intention is to identify and exclude CEs from Research Outputs in future releases.
Back to table of contents3. Main points
These are the first Administrative Data Research Outputs on estimating the number of households in England and Wales. They’re the start of the research to see if it’s feasible to produce household estimates from administrative data.
Household estimates produced from the census and the Labour Force Survey (LFS) use a definition based on “shared facilities”1. We’re currently unable to produce estimates based on this definition from administrative data. Instead, when we refer to “household estimates” in this release, we really mean “an estimate of occupied addresses from administrative data”.
We’re therefore keen to understand how well these household estimates meet user needs for household statistics. This is compared with household estimates produced for the definition currently collected from census and surveys. We’d also like to understand whether households defined as dwelling units may be a more robust definition for a future census that relies predominantly on administrative data. Please email your comments to Admin.Data.Census.Project@ons.gov.uk.
We’ve produced these household estimates at regional and local authority level for England and Wales by linking individuals and their address records across 5 datasets. These datasets are:
the NHS Patient Register
Department for Work and Pensions Customer Information System
English School Census
Welsh School Census
Higher Education Statistics Agency data
This publication focuses on the coverage and quality of our initial Research Outputs from these administrative sources. Estimates have been produced for years 2011 and 2015 and comparisons made with official Office for National Statistics (ONS) estimates from the census in 2011 and the LFS in 2015.
These Research Outputs estimate lower numbers of households using an “occupied address” definition from administrative data. Household estimates are lower for local authorities by an average of 5.6% when compared with 2011 Census estimates.
The approach we’re developing with administrative data has the potential to deliver estimates of the number of households for small areas more often than the current approach. There’s also potential to produce detailed tabulations based on other household characteristics.
Notes for: Main points
- The 2011 Census defines households as “one person living alone, or a group of people (not necessarily related) living at the same address who share cooking facilities and share a living room or sitting room or dining area”.
4. Household definitions
The 2011 Census defines households as:
“One person living alone, or a group of people (not necessarily related) living at the same address who share cooking facilities and share a living room or sitting room or dining area”…
“A household must contain at least one person whose place of usual residence is at the address. A group of short-term residents living together is not classified as a household, and neither is a group of people at an address where only visitors are staying”.
The ONS Labour Force Survey (LFS) is used to produce estimates for the number of households in England and Wales in between census years1. It uses the same household definition as the 2011 Census.
The focus on shared facilities in the definition serves an important purpose in distinguishing between multiple households that occupy the same residential property. It’s often the case that there’s a one-to-one relationship between a household and a residential address. However, cases where multiple households occupy the same address are referred to as houses in multiple occupation (HMOs).
In the case of administrative data, it may not be possible to identify HMOs from the address information collected from individuals. Often these addresses will be a single residential address that appears to be occupied by a large number of residents. Without additional information about the residents and the relationships between them, it’s difficult to tell when there are multiple households living at the same address.
Communal establishments
Both the census and the LFS exclude communal establishments from statistics produced about households. The 2011 Census had a separate strategy for collecting information and producing estimates about the number of communal establishments. In this first release, these Research Outputs include communal establishments. This is because we’re yet to develop a method for identifying and excluding them from Statistical Population Dataset (SPD) V2.0. We’re researching the potential for classifying communal establishments in administrative data and will aim to exclude them from future releases.
Countries with “register-based” censuses
Some countries that have a register-based census use alternative definitions of a household. The United Nations Statistics Division highlights use of the “dwelling household” concept, where a household consists of all persons living together in a housing unit. An example is Finland, where “household-dwelling unit” consists of the permanent occupants in a dwelling.
We also note the work of Harper and Mayhew (2015) in this area, who have developed alternative household classification systems using administrative data2.
We’re interested in hearing your views about your requirements for household statistics. Surveys might be used to target this definition for combined use with administrative data. However, it’s possible that households as dwelling units may be a more robust definition for a future census that relies mainly on administrative data. We encourage you to email Admin.Data.Census.Project@ons.gov.uk to share your views with us about household definitions and other content on these Research Outputs.
Other differences between these outputs and those from official statistics
In addition to the definitional differences highlighted in this section, there are some other important distinctions between the household estimates produced in these Research Outputs and those published in official statistics. These are that:
occupied addresses on administrative data include those with at least one “usual resident” included in SPD V2.0; more information about the construction of SPD V2.0 and our administrative data population estimates is available in a previous methodology article
only occupied addresses that have been successfully linked to a unique property reference number (UPRN)3 on AddressBase4 have been included in these research outputs
We aim to develop the methodology for producing household estimates with the combined use of surveys and additional data sources in the future. That said, our report sets out a number of challenges associated with producing household estimates from administrative data. Censuses and surveys can be designed to collect information from households. However, administrative data is primarily collected from individual persons interacting with government services, such as tax and benefits, GPs, schools and universities. Members of the same household won’t always interact with government services at the same time. This can result in inaccurate records of who is living at addresses. This is particularly the case when people move addresses and their information isn’t updated.
Notes for: Household definitions
The Welsh government produces separate annual official household estimates for Wales. These are based on a different methodology from ONS estimates produced from the LFS and aren’t used as the basis of comparison in this report.
Harper,G. and Mayhew, L., 2015, Using Administrative Data to Count and Classify Households with Local Applications, Appl. Spatial Analysis DOI 10.1007/s12061-015-9162-2.
A unique property reference number (UPRN) is a unique alphanumeric identifier for every spatial address in Great Britain and can be found in Ordnance Survey's address products.
AddressBase – an Ordnance Survey address product compiled from local authority, Ordnance Survey and Royal Mail address lists.
5. Methodology
These Research Outputs are taken from the same usual resident population base that has been used for the previously released Administrative Data Research Outputs. The Statistical Population Dataset (SPD V2.0) – constructed by linking multiple administrative datasets – was used as the basis for Research Outputs released in November 2016 on size of the population. A previous version of this dataset (SPD V1.0) was used to produce Research Outputs on income from PAYE and benefits for the tax year in 2014. These were published in December 2016.
Household estimates for these Research Outputs have been produced by linking address records from 3 administrative datasets. These are:
the NHS Patient Register (PR)
the Department for Work and Pensions Customer Information System (CIS)
the English School Census (ESC)
These data sources form part of a wider set of administrative records that have been combined to produce SPD V2.0. For a detailed report on the methodology for constructing SPD V2.0 and the rules used to produce population estimates, see our methodology for producing population estimates from administrative data.
The first step in our methodology is to link the address records on the administrative datasets to a standardised address identifier. For these Research Outputs, we’re using the unique property reference number (UPRN) that’s been referenced to all residential addresses in England and Wales on AddressBase. Due to inconsistencies in the recording of address information collected on administrative sources (see Figure 1) it’s necessary to match and resolve multiple formats of an address to a standardised reference number. Figure 1 demonstrates how the same address can be collected differently on administrative sources but linked to the same UPRN on AddressBase.
Figure 1: Resolving inconsistencies in the recording of address records
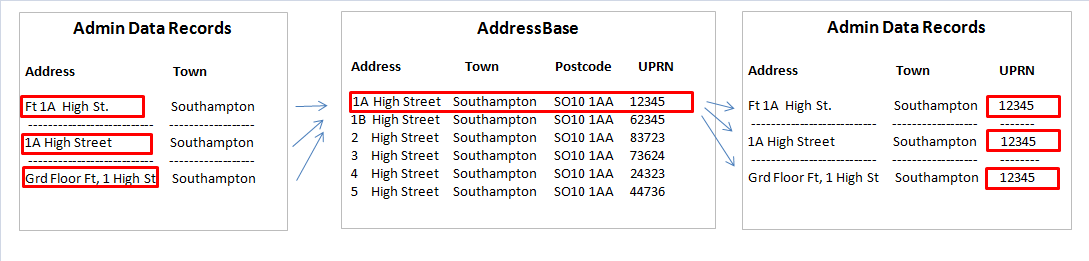
Source: Office for National Statistics
Notes:
UPRN - Unique Property Reference Number.
The above example is illustrative only and doesn't relate to real address records.
Download this image Figure 1: Resolving inconsistencies in the recording of address records
.png (22.5 kB)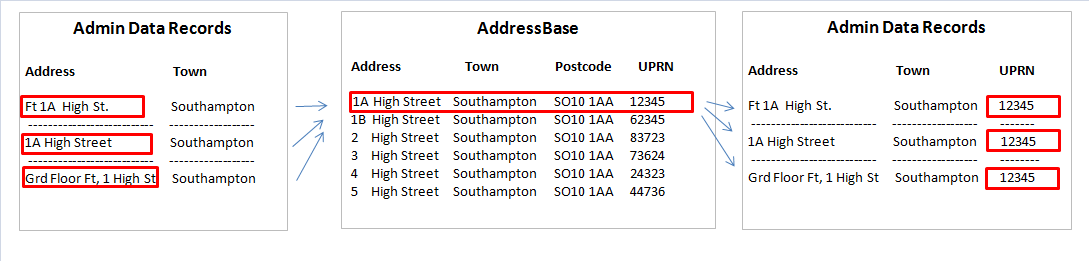{kind=link}
We’ve developed an automated matching methodology that links address records to AddressBase to assign a UPRN. The PR, CIS and ESC are all supplied to the Office for National Statistics (ONS) with individuals’ address records. However, 2 additional datasets used in the construction of SPD V2.0 don’t include detailed information about individuals’ addresses. These are:
the Welsh School Census (WSC)
data from the Higher Education Statistics Agency (HESA)
Currently we only have address information at postcode level from these 2 sources. While detailed address information for students is collected, it isn’t currently included in the HESA dataset supplied to ONS. In the case of the WSC, detailed address information isn’t collected from pupils attending Welsh schools.
Our administrative data population estimates methodology relies on matching individuals across multiple datasets using various combinations of name, sex, date of birth and postcode. More information about our methodology is available in our matching methodology article. In many cases, people registered as living at different postcodes across administrative sources can still be linked and included in our administrative data population estimates.
For these cases, a hierarchy is needed to determine at which location to count people in the population estimates. Students, for example, often have conflicting information regarding their location when comparing the postcodes recorded on different sources. We include students in the term-time postcodes recorded on HESA as this data is collected annually from universities.
A similar situation occurs on SPD V2.0 with pupils recorded on the WSC. We include all pupils at the home postcode recorded on WSC as it’s collected annually from schools. Without detailed address information on both HESA and the WSC, we’ve developed a methodology to assign these records to a UPRN in the same postcode. This is described in the next section.
Assigning a UPRN to records on SPD V2.0
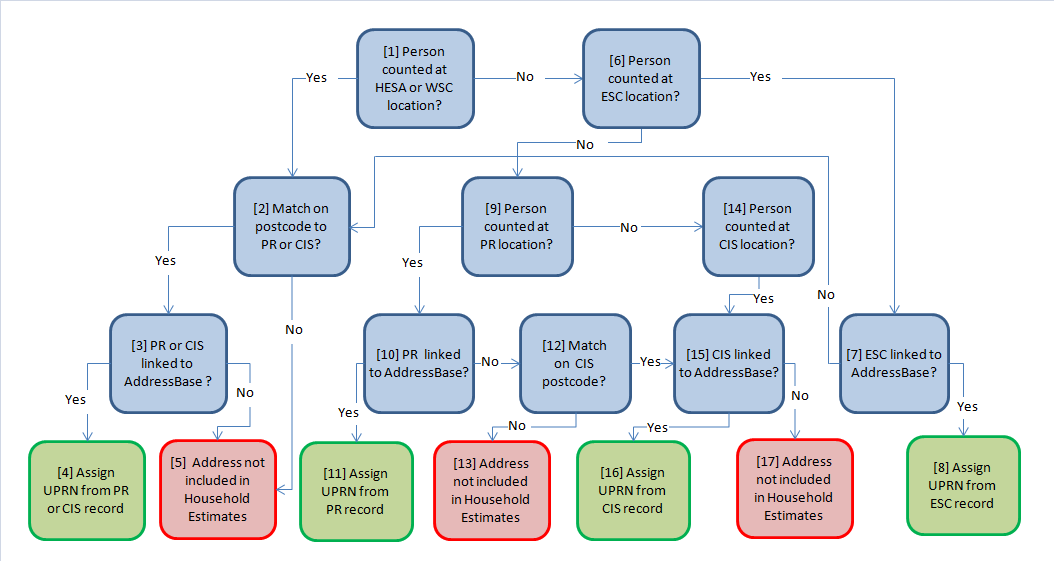
Our methodology for producing household estimates relies on assigning a UPRN to records at the location that the person has been counted in the SPD V2.0 population estimates. Figure 2 explains the hierarchy for assigning UPRNs to records on SPD V2.0.
Figure 2: Hierarchy for UPRN assignment on SPD v2.0 records
Source: Office for National Statistics
Notes:
UPRN - Unique Property Reference Number.
SPD - Statistical Population Dataset.
CIS - DWP Customer Information System.
ESC - English School Census.
WSC - Welsh School Census.
HESA - Higher Education Statistics Agency data.
PR - NHS Patient Register.
Download this image Figure 2: Hierarchy for UPRN assignment on SPD v2.0 records
.png (34.1 kB)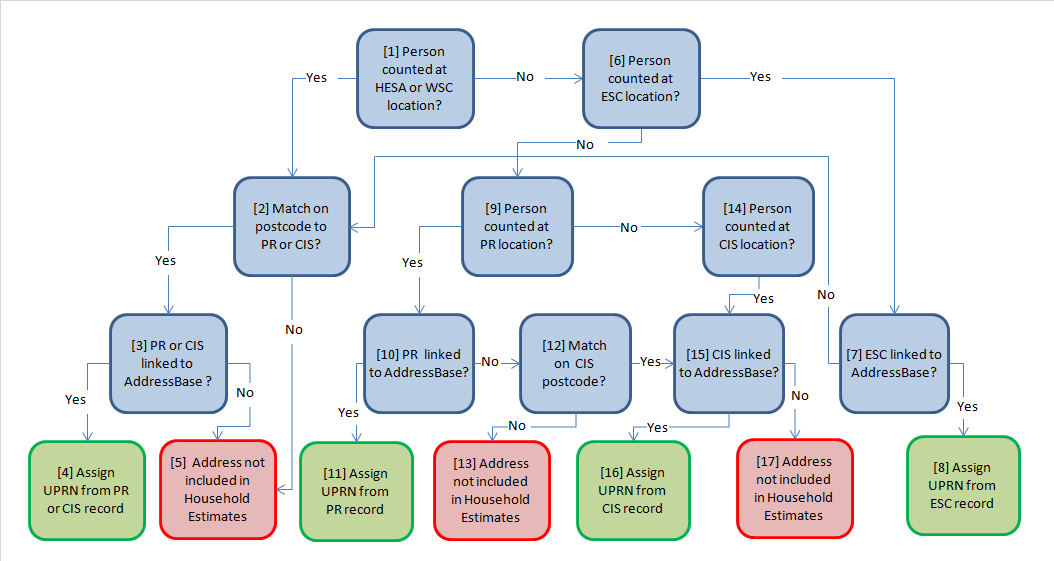{kind=link}
The first step depends on whether the individual is a student recorded on HESA or a pupil registered on WSC, (1) in Figure 2. Since detailed address information isn’t available from these sources, we observe whether we’ve linked the individual to a record on the PR or CIS that shares the same postcode as HESA (2). If either address is within the same postcode and has been matched to a UPRN on AddressBase (3), we can assign the UPRN to the HESA record (4). If a match within the same postcode can’t be made to PR or CIS or where the UPRN isn’t available from either of these 2 sources, the person can’t be assigned a UPRN. Their address record won’t be included in the household estimates (5).
The next step depends on whether the individual is recorded on the ESC (6). Address details are available on ESC, so we observe whether a direct link to a UPRN on AddressBase was made (7). If so, the UPRN is assigned from the linked ESC address (8). If the address hasn’t linked to AddressBase, we follow the same process for HESA and WSC records and look for a match at the same postcode on PR or CIS (2).
The remaining records on SPD V2.0 are those that appear in both the PR and the CIS. If the person has been counted at the PR location (9), and a direct link has been made between the address on PR and AddressBase (10), the resulting UPRN can be assigned (11). If the PR address hasn’t successfully matched to AddressBase, we can observe whether the person’s CIS record has the same postcode (12). If so, and the CIS address has been successfully linked to AddressBase, we can assign the UPRN on the CIS record (15) and (16).
The final stage of our hierarchy is for records that have been counted at the CIS location (14). These records don’t agree on location with the PR so can only be assigned the UPRN from a direct match on addresses between the CIS and AddressBase (15) and (16).
The algorithm shown in Figure 2 has been developed to assign UPRN to SPD V2.0 records in the locations that they have been counted in the administrative data population estimates. Overall, records that can’t be assigned to a UPRN make up 4.2% of records on SPD V2.0 in 2011. As a result, many of the addresses occupied by these residual records may be missing from the household estimates produced from this methodology. This is only the case if none of the residents registered at the address have been assigned with a UPRN. While we can’t measure this directly, this is one of a number of factors that can account for household estimates being lower using administrative data. A more detailed discussion of SPD V2.0 records that haven’t been assigned to a UPRN is provided in section 6.
Quality of addresses on administrative sources
While the PR, CIS and ESC include detailed address information, not all of those addresses can be successfully matched to AddressBase. Broadly, there are 3 reasons for this:
the address fields haven’t been completed
the address information provided isn’t of adequate quality to identify a match
the address provided isn’t listed on AddressBase
Currently, the match rates of administrative sources linked to AddressBase using our automated algorithm range from between 95% and 98%. We continue to review our methods for linking data with the expectation that we can improve quality in future.
Complex addresses
Another issue that’s likely to be impacting on the SPD V2.0 estimates is the granularity of address information available on AddressBase. Properties with more complex address structures (for example, residential houses that have been converted into separate flats) won’t always have information supplied about the hierarchy of addresses contained within the same building. In these circumstances, a “parent” and “child” UPRN structure is needed to ensure that each of the flats can be identified separately. Figure 3 illustrates 2 examples of multiple flats within the same building, one of which has “child” UPRNs assigned, one without.
Figure 3: "Parent" and "Child" UPRN structures
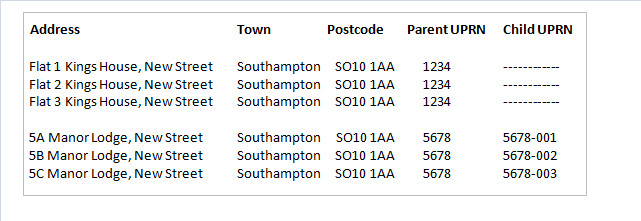
Source: Office for National Statistics
Notes:
UPRN - Unique Property Reference Number.
The above example is illustrative only and doesn't relate to real address records.
Download this image Figure 3: "Parent" and "Child" UPRN structures
.png (10.9 kB){kind=link}
In the first example, “child” UPRN hasn’t been assigned to the 3 separate flats at the address. If each of these flats had 2 people living in them, we would observe 6 people living as 1 household (based on the parent UPRN), rather than 3 households, each with 2 people.
In areas where there are higher concentrations of flats, there’s a risk that household estimates will be low as a result of multiple households being grouped together as single households. The assignment of “child” UPRNs, as with the second example, is needed to discern between separate households living at the same address.
In describing our methodology, we’ve highlighted several factors that contribute to the number of households being lower than official estimates using administrative data. A more complete summary of all issues impacting the quality of household estimates produced from SPD V2.0 is provided in the conceptual framework in Figure 4.
Figure 4: Conceptual framework accounting for differences in household estimates from administrative data

Source: Office for National Statistics
Notes:
SPD - Statistical Population Dataset.
UPRN - Unique Property Reference Number.
Download this image Figure 4: Conceptual framework accounting for differences in household estimates from administrative data
.png (210.7 kB){kind=link}
The differences observed between SPD V2.0 household estimates and official household estimates can be due to a range of issues. Some of these relate to quality issues with address information, as described in this section. However, there is also the issue that SPD V2.0 household estimates are derived from a population base that is known to have coverage error. An analysis of population coverage on SPD V2.0 is available in our size of population analysis report. In future, we’ll research methods to improve the coverage of both population and household estimates.
Back to table of contents6. Analysis of SPD V2.0 household estimates
This section of our report compares estimates for the number of households using the Statistical Population Dataset (SPD) V2.0 methodology with our household estimates from the 2011 Census and the Labour Force Survey (LFS) in 2015.
Since the 2011 Census is the most recent estimate of the number of households at local authority level, most of our analysis focuses on 2011. Comparisons with the LFS in 2015 are limited to regional level, as this is the lowest level of geography that household estimates are published for. One of the benefits of an administrative data census is that household estimates for smaller areas could be produced more often.
There are Research Output tables accompanying this report. The analysis presented highlights possible reasons for the differences observed between these Research Outputs and official household estimates.
2011 comparisons
Figure 5 shows a regional comparison of census and SPD V2.0 household estimates for 2011.
Figure 5: Household estimates comparison between SPD V2.0 and 2011 Census
England and Wales
Source: Office for National Statistics
Notes:
- SPD - Statistical Population Dataset
Download this chart Figure 5: Household estimates comparison between SPD V2.0 and 2011 Census
Image .csv .xlsIn all regions, SPD V2.0 estimates of the number of households are notably lower than the 2011 Census estimates. London in particular has the most notable difference, with SPD V2.0 estimates for the number of households 11.9% lower than the census (2.9 million compared with 3.3 million). For all other regions the difference is smaller, with estimates ranging from 4.2% lower in the North East to 6.4% lower in Wales.
At local authority level, household estimates from SPD V2.0 are lower by an average of 5.6% when compared with the 2011 Census. This difference is greater than comparisons of population size between SPD V2.0 and 2011 Census, where on average local authorities are only 0.1% lower. Figure 6 shows the distribution of differences for local authorities comparing household and population estimates between SPD V2.0 and the 2011 Census.
Figure 6: Distribution of differences between SPD V2.0 and 2011 Census, household and population size estimates, local authorities
England and Wales
Source: Office for National Statistics
Notes:
- SPD - Statistical Population Dataset
Download this chart Figure 6: Distribution of differences between SPD V2.0 and 2011 Census, household and population size estimates, local authorities
Image .csv .xlsFigure 6 shows that the distribution of local authority population estimates on SPD V2.0 are closer to the 2011 Census estimates. For estimates of the number of households, there’s a clear tendency for local authority estimates on SPD V2.0 to be lower than the 2011 Census.
Only 1 local authority estimates a larger number of households from SPD V2.0 than the 2011 Census. This is Oadby and Wigston, which is 0.2% higher. The population estimates for Oadby and Wigston are also slightly higher than the 2011 Census (1.0%). However, other local authorities estimating higher populations on SPD V2.0 don’t correspond with higher estimates for the number of households. Population estimates in Oadby and Wigston are particularly high for 25 to 29 year old males. This may reflect student populations that have left nearby Leicester University and not de-registered with GPs in the area of study. One possible explanation for the relatively higher number of household estimates in Oadby and Wigston is that vacant unique property reference numbers (UPRNs) previously occupied by students before 2011 still appear occupied as a result of not de-registering with GPs.
Another explanation is that some of the addresses relating to student halls being counted in Oadby and Wigston would be counted as communal establishments in the 2011 Census.
There are 28 local authorities with household estimates more than 10% lower than the 2011 Census. The 20 local authorities with the largest differences are highlighted in Figure 7.
Figure 7: The 20 local authorities with largest differences in SPD V2.0 household estimates compared with the 2011 Census
England and Wales
Source: Office for National Statistics
Notes:
- SPD - Statistical Population Dataset.
Download this chart Figure 7: The 20 local authorities with largest differences in SPD V2.0 household estimates compared with the 2011 Census
Image .csv .xlsSince we’re using the SPD V2.0 population base to produce these household estimates, we anticipate that local authorities with lower estimates of population size will also have lower estimates for the number of households. With the exception of City of London, all of the local authorities appearing in Figure 7 also have lower estimates of population size when comparing SPD V2.0 with the 2011 Census.
A large number of local authorities in Figure 7 comprise of London boroughs. Household estimates for City of London are particularly low with SPD V2.0 estimating 50.6% lower than the 2011 Census. As a small central business district, the area is likely to have a large proportion of complex residential addresses, making UPRN assignment more problematic.
The London boroughs of Kensington and Chelsea, and Westminster also have notably lower SPD V2.0 household estimates than the 2011 Census (negative 34.6% and negative 31.5% respectively). These boroughs were highlighted in our analysis of SPD V2.0 population estimates for being notably lower than the 2011 Census population estimates. However, the magnitudes of difference for household estimates are greater than the differences observed in population estimates, where population size for Kensington and Chelsea was estimated to be 21.0% lower and Westminster 15.2% lower.
There are 2 Welsh local authorities appearing in Figure 7 with notably lower SPD V2.0 household estimates compared with the 2011 Census. SPD V2.0 estimates for Gwynedd are 21.4% lower than the 2011 Census and Anglesey 11.9% lower. In the case of Gwynedd (where Bangor University is situated) failures to assign UPRNs to Higher Education Statistics Agency (HESA) records, as described in section 5, may have resulted in occupied addresses being excluded from the SPD V2.0 household estimates.
Potential explanations for Anglesey are less forthcoming. Linking address records on administrative data to AddressBase is likely to be more problematic if components of addresses have been recorded in Welsh language. However, we wouldn’t necessarily expect this issue to be more prominent in Anglesey than in other Welsh authorities. Due to the pseudonymisation process that we’re using to safeguard administrative data, we currently have limited capacity to investigate why SPD V2.0 address records have lower rates in some areas. We’re currently reviewing our approach to record linkage at ONS and may have more opportunities to explore the situation in Anglesey in more detail in future.
Forest Heath also appears in Figure 7, with SPD V2.0 household estimates 13.7% lower than the 2011 Census. As discussed in our analysis of SPD V2.0 population estimates, we currently don’t have access to record level data for armed forces personnel, which are known to make up a significant proportion of the population in Forest Heath. This has the potential to result in the dependants of armed forces personnel being missing from the SPD V2.0 population estimates. The exclusion of these individuals from SPD V2.0 may also have resulted in the exclusion of addresses they are occupying from our household estimates.
It’s likely there are a number of factors contributing to the increased level of difference between household estimates in these areas. As described in section 5, records that can’t be assigned to UPRN are likely to have resulted in a number of occupied addresses being missed in the SPD V2.0 estimates. The scatter plot in Figure 8 shows the relationship between lower household estimates and the percentage of records that are unassigned to a UPRN on SPD V2.0.
Figure 8: Percentage of SPD V2.0 records unassigned to UPRN and differences in household estimates from 2011 Census, local authorities
England and Wales
Source: Office for National Statistics
Notes:
SPD - Statistical Population Dataset.
UPRN - Unique Property Reference Number.
Download this chart Figure 8: Percentage of SPD V2.0 records unassigned to UPRN and differences in household estimates from 2011 Census, local authorities
Image .csv .xlsFailures to assign a UPRN to individuals counted in the SPD V2.0 population estimates increases the risk that occupied addresses will be excluded from our SPD V2.0 household estimates. Figure 8 shows that local authorities with the largest differences in estimating the number of households also have a higher percentage of records that can’t be assigned to a UPRN.
Areas with large student populations
Without detailed address information available on HESA, areas with large proportions of students in the population are more likely to result in lower household estimates when comparing SPD V2.0 with the 2011 Census. Only students that have been successfully linked to a Patient Register or Customer Information System record that matches the same HESA term time postcode will be assigned to a UPRN. Figure 9 shows the percentage of SPD V2.0 records unassigned to a UPRN for the 10 local authorities with the largest proportion of students in the population. It also provides a breakdown of record type for unassigned UPRNs, showing the proportion that can be attributed to HESA records.
Figure 9: Percentage of SPD V2.0 records unassigned to UPRN for the top 20 local authorities with the highest proportion of students in the population
Source: Office for National Statistics
Notes:
SPD - Statistical Population Dataset.
UPRN - Unique Property Reference Number.
HESA - Higher Education Statistics Agency.
Download this chart Figure 9: Percentage of SPD V2.0 records unassigned to UPRN for the top 20 local authorities with the highest proportion of students in the population
Image .csv .xlsLocal authorities with larger proportions of students have a higher percentage of SPD V2.0 records that can’t be assigned to a UPRN. Figure 9 shows that in some cases, for example, in Exeter, Southampton, Welwyn Hatfield, Lancaster and Oxford, the majority of records unassigned to UPRN can be attributed to student records on HESA. However, amongst London boroughs with large proportions of students in the population, HESA records have a smaller contribution to the overall percentage of records that can’t be assigned a UPRN.
2015 comparisons between SPD V2.0 and the Labour Force Survey
Official ONS estimates for the number of households between census years are produced from the ONS Labour Force Survey (LFS). These are published at national level for England and Wales. More information about the official household estimates produced from the LFS is available in the Quality and Methodology Information report. LFS data isn’t used to produce official estimates of the number of households at regional level. However, they are produced and published on our website as part of a user-requested data service. Estimates at local authority level aren’t published but are available on request.
Regional household estimates from LFS data have been published for 2015. We’ve used these as the basis for comparison against SPD V2.0 in the same year.
One of the advantages of an administrative data census is the potential to produce household estimates for small areas more often. These can also possibly be combined with other tabulations on household characteristics.
Figure 10 shows that while SPD V2.0 is still estimating lower numbers of households in all regions, the difference has narrowed, particularly in London.
Figure 10: Household estimates comparison between SPD V2.0 and LFS 2015, England and Wales regions
England and Wales
Source: Office for National Statistics
Notes:
SPD - Statistical Population Dataset.
LFS - Labour Force Survey.
Download this chart Figure 10: Household estimates comparison between SPD V2.0 and LFS 2015, England and Wales regions
Image .csv .xlsFigure 11 below shows the percentage difference of SPD V2.0 household estimates from official 2011 Census estimates and published LFS estimates in 2015 for all regions.
Figure 11: Percentage differences comparing SPD V2.0 with 2011 Census and SPD V2.0 with LFS 2015 for number of households, England and Wales regions
Source: Office for National Statistics
Notes:
SPD - Statistical Population Dataset
LFS - Labour Force Survey.
Download this chart Figure 11: Percentage differences comparing SPD V2.0 with 2011 Census and SPD V2.0 with LFS 2015 for number of households, England and Wales regions
Image .csv .xlsFor the East of England, North East, West Midlands and Wales, the difference between SPD V2.0 and LFS household estimates in 2015 has increased when compared to differences observed in the 2011 comparison with Census estimates. However, the difference between SPD V2.0 and LFS household estimates in 2015 has narrowed for all other regions, particularly London and the South East.
This improvement is partly reflected in the increased success rate in assigning SPD V2.0 records to a UPRN in 2015. Overall, the number of “residual” records that are left unassigned has dropped from 4.2% to 3.6%. The same matching methodology has been used to link addresses to AddressBase in both 2011 and 2015. However, it may be the case that the quality of address information that we’re using has improved during the period between 2011 and 2015.
We haven’t yet carried out detailed research to understand these improvements in the SPD V2.0 match rate to UPRNs. Possible explanations may include increased coverage and quality of address records being supplied to AddressBase – for example, improved coverage of more complex addresses with “parent” and “child” UPRN hierarchies. It may also be the case that the quality of addresses collected on the administrative datasets has improved.
Figure 12 highlights the top 20 local authorities with increases in the percentage of SPD V2.0 records that have been successfully assigned to UPRN in 2015 compared with 2011.
Figure 12: Top 20 local authorities with an increase in the number of SPD V2.0 records assigned to a UPRN
Source: Office for National Statistics
Notes:
- SPD - Statistical Population Dataset
- UPRN - Unique Property Reference Number
Download this chart Figure 12: Top 20 local authorities with an increase in the number of SPD V2.0 records assigned to a UPRN
Image .csv .xlsCity of London has most notably improved with a 36.8% increase in UPRN assignment in 2015 compared with 2011. Figure 12 shows that a number of London boroughs have seen an increase in the percentage of records successfully assigned to UPRN in 2015. These include Westminster, where UPRN assignment increased by 8.4% and Kensington and Chelsea, where UPRN assignment increased by 5.2%. Both of these local authorities were highlighted earlier in this section for having notably lower SPD V2.0 household estimates in 2011 when compared with the 2011 Census.
The scatter plot in Figure 13 shows the percentage of records unassigned to UPRN on SPD V2.0 compared between 2011 and 2015 for all local authorities. The majority of local authorities have seen a small reduction in the percentage of unassigned records to UPRN. Most notable improvements are for local authorities that had the highest percentage of unassigned records in 2011.
Figure 13: Percentage of SPD V2.0 records not assigned a UPRN in 2011 and 2015, local authorities
Source: Office for National Statistics
Notes:
SPD - Statistical Population Dataset.
UPRN - Unique Property Reference Number.
Download this chart Figure 13: Percentage of SPD V2.0 records not assigned a UPRN in 2011 and 2015, local authorities
Image .csv .xls7. Summary and next steps
These Research Outputs are our first attempt at producing estimates for the number of households using administrative data. There are limitations in meeting a traditional definition of “household” using administrative data. However, improvements in the coverage of addresses in administrative data for 2015 shows potential for household estimates to become better over time.
In future, we’ll research the potential to combine administrative data with surveys to improve the coverage of household estimates and adjust for the definitional differences in the administrative data.
As part of our engagement with users of census statistics, we’ll be giving further consideration to definitions that may be more suitable for an administrative data census. We’re keen to work with users of our statistics to discuss whether a change in definition would meet their information needs about households in future.
Based on the comparisons highlighted in this report, Statistical Population Dataset (SPD) V2.0 household estimates based on our current methodology result in lower estimates when compared with the 2011 Census and Labour Force Survey (LFS) estimates in 2015. Aside from definitional differences, main reasons for this can be summarised as:
UPRN assignment – Not all records on SPD V2.0 can be assigned to a unique property reference number (UPRN) due to missing address information or failures to link addresses
complex residential addresses – Addresses with “parent” and “child” UPRN hierarchies are unlikely to have full coverage on the administrative data we’re using for these research outputs
SPD V2.0 inclusion rules – The rules used to determine usual residence in our SPD V2.0 population estimates may have resulted in the incorrect exclusion of some households from our population base
As with a number of outputs we plan to produce in our research into an administrative data census, one of the advantages of this kind of approach is the potential to produce more regular statistics at small area level. We anticipate that methodological improvements can be made to improve on the challenges highlighted in this conclusion and future Research Outputs on household size and household composition will be the focus of subsequent releases.
These Research Outputs would also benefit from improvements in the administrative data we’re using to produce the household estimates. In particular, we’re interested in receiving more detailed address information for students recording on the Higher Education Statistics Agency (HESA).
Currently, official household statistics of this type can’t be produced in between census years. These Research Outputs have the potential to offer a wider range of outputs on households in England and Wales. Future engagement with stakeholders will focus on users’ information requirements for new statistics that might be achievable with administrative data. We’d appreciate it if you could complete our feedback survey to help us develop our methods for household estimates in future Research Output releases.
Back to table of contents