1. Introduction
The Wealth and Assets Survey (WAS), which commenced in July 2006, covered a two-year period that started in July and ended in June two years later. This periodicity is referred to as a “wave”. Wave 1 of the survey covered the period July 2006 to June 2008 with this periodicity maintained until wave 5, which covered the period July 2014 to June 2016.
The survey period is now moving to a two-year, financial year-based periodicity (April to March) with this periodicity being referred to as a “round”. Therefore, round 6 will cover the period April 2016 to March 2018. This move to a two-year, financial year basis allows WAS to be integrated with other household financial surveys that are based on financial years. This allows WAS to be analysed on a consistent basis alongside other components included within other household financial surveys (income and expenditure).
Back to table of contents2. The Household Finance Survey
As part of the Office for National Statistics (ONS) Data Collection Transformation Programme (DCTP), several surveys have been brought together to form the Household Finance Survey (HFS). The aim of this survey is to provide coherent data on household incomes, consumption and wealth. The survey will comprise a core set of questions covering topics such as economic activity, housing, tenure, income (and benefits), pensions and investments and material deprivation. There will be modules covering topics on detailed income, consumption and wealth, as well as areas of policy interest.
The development of the HFS has taken an iterative approach, which started with the integration in 2017 of the Living Costs and Food (LCF) survey and Survey on Living Conditions (SLC) sample designs, and the harmonisation of questions about employment, income and material deprivation. This development supported the production of coherent, precise income and living conditions statistics from the combined surveys. The combined annual sample size of these two surveys is approximately 17,000 households.
The next stage of development involves integrating WAS. This would add a further 9,000 to 10,000 households per year.
The survey periods for both the LCF and the SLC are based on financial years. For WAS to become part of the HFS, the survey period needed to move to a financial year basis.
The Household Finance Survey Model is shown in Figure 1.
Figure 1: Household Finance Survey model
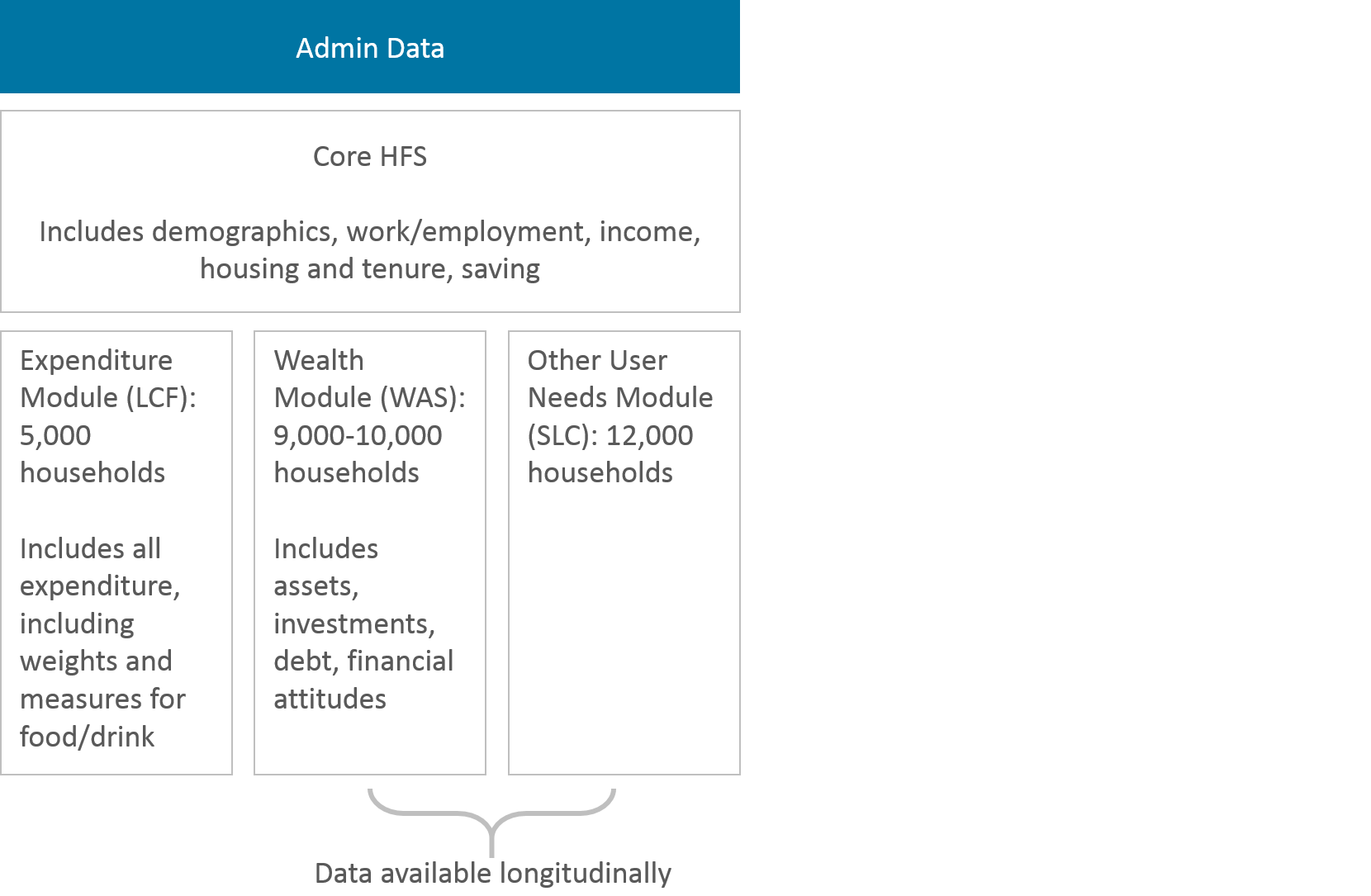
Source: Office for National Statistics
Download this image Figure 1: Household Finance Survey model
.png (83.0 kB){kind=link}
3. Moving from waves to rounds
Wave 6 of the Wealth and Assets Survey (WAS) started in July 2016 but ran for only 21 months to March 2018.
Data for round 6, covering the period April 2016 to March 2018, will comprise the last three months of wave 5 (April to June 2016) and 21 months of wave 6 (July 2016 to March 2018).
Round 7 of WAS commenced in April 2018 and will run for two years (ending in March 2020). A level of integration took place with the other HFS surveys, with a common sample being drawn for all three surveys, and harmonisation of some income questions across the surveys.
WAS will continue to use a two-stage or "clustered" approach to sampling with postcode sectors being the primary sampling units (PSUs) for the survey. Previously, PSUs were randomly selected from the Postcode Address File (PAF) and addresses randomly selected from within each of these.
In future, to integrate the WAS sample with the HFS, addresses will be selected from within the previous year’s SLC PSUs. This improves the efficiency of fieldwork as interviews will already need to be conducted in these areas for the next round of SLC. Where there are not enough SLC PSUs then LCF PSUs will be used instead. To ensure the same address is not selected for more than one survey, every time an address is selected for a social survey it becomes ineligible for selection for any other social survey for a period of time.
The “overlap” period
The change to financial years will lead to a shift in the WAS time series. To assess the effect on WAS, estimates have been produced for a common “overlap” period: both wave 5 (July 2014 to June 2016) and round 5 (April 2014 to March 2016) datasets have been produced. Estimates have been presented later in this article and a full set of datasets is available.
Many processing practices have changed over the life of the survey and it is not practical to produce round-based estimates historically. In particular, the weighting process was only fully automated in wave 5 and before this contained many manual steps. Therefore, round-based estimates will start from round 5 onwards. Longitudinal analysis is still possible and is discussed in detail within the section Longitudinal weighting of the survivors’ dataset.
Back to table of contents4. Production of round-based datasets
Round 5 and round 6 datasets will be based on a mixture of original wave-based datasets. Each wave of the survey has a unique questionnaire and therefore each of these round-based datasets will be based on two questionnaires. While there may be some changes in the questionnaires, the derived variables for the key wealth estimates have not changed over this period. The aim is to collect the same data, though in some cases the exact questions asked may differ slightly.
On the round 5 datasets, the question variables will be included with the W4 or W5 suffix. Where wave 4 and wave 5 derived variables are consistent, the variables will be renamed with an R5 suffix at the end. Where a consistent round 5 derived variable cannot be created, the wave 4 and wave 5 derived variables will remain on the dataset with a W4 or W5 suffix. All wave 5 derived variables were also created in wave 4 so a round 5 version can be created.
There are some wave 4 derived variables that were not created in wave 5. These are only “interim” derived variables, which are variables created to produce the final derived variables needed for analysis. For example, the interim derived variables for the value of all cars, value of all motorbikes and value of all vans was created on the wave 4 dataset, as well as the final derived variable for value of all motor vehicles; in wave 5 (and therefore round 5) there is only the final derived variable for the value of all motor vehicles.
For round 6, there will be a small number of derived variables which cannot be created consistently across wave 5 and wave 6 as the necessary questions were not included on the wave 5 questionnaire (for example DVTOT_Mort_int1w6 – Annual mortgage interest from main home) or the input questions differed considerably, and a variable is renamed between waves to indicate the inconsistency. A full list of derived variables which cannot be created for round 6 will be published alongside the round 6 datasets with details of any inconsistencies. If necessary, advice will be given on how problematic variables might best be analysed.
There are many variables on the datasets which do not feed into derived variables but are useful in their own right, for example debt burden and other opinion-type questions. These will be on the round 5 dataset with a W4 or W5 suffix and analysts will need to ensure their consistency before using them by renaming both with an R5 suffix. Where there are differences, analysts will need to decide if the differences are enough to affect any analyses undertaken.
Back to table of contents5. Weighting methodology
This section considers the current weighting strategy and the revised approach taken to produce financial year-based weights.
Overview of current weighting methodology
Currently, weights are produced for the Wealth and Assets Survey (WAS) for two purposes:
The Early indicators publication, where weights are calculated based on 6, 12 and 18 months of data from each wave
the Wealth in Great Britain publication, where weights are calculated for the full two years of the wave
The same basic weighting methodology is applied to both cases; the only difference is in exactly which weights are produced and the amount of data used to produce them. There are three basic types of WAS weights:
longitudinal “survivor” weights, which are calculated for individuals who respond in every wave
longitudinal T-1 to T weights, which are calculated for individuals responding both in the previous and the current wave
cross-sectional weights (both at the person and household level) for cases that respond in the latest wave, with a separate weight being produced using non-proxy individual respondents
The weighting methodology is described in detail in the Survey Methodology Bulletin (PDF, 1.5MB). The basic principle is that the weights from the last wave are used as the base weights in the current wave. The way of entering the sample is also important, particularly in the cross-sectional weighting where different treatments are applied. This includes new panel members sampled for the first time, joiners to households, entry original sample members (those responding for the first time in the current wave, despite being sampled in an earlier wave), births, and re-entrants (individuals who respond in the current wave, having last responded in a wave prior to the previous wave). For both the cross-sectional and longitudinal T-1 to T weighting, the weights are calibrated separately for each panel (the WAS sample now comprises panels sampled in waves 1, 3, 4, 5 and 6 – a new cohort was not introduced in wave 2) before being combined in proportion to their effective sample size.
Weighting methodology for round-based weights
Round 5 weights
The starting point for calculating round 5 weights was the existing longitudinal and cross-sectional weights calculated on a wave basis. As already discussed it was not practical or feasible to reweight the entirety of WAS using the new approach, meaning that analysts will continue to use the existing wave-based weights and the corresponding wave datasets for waves 1 to 4 (July 2006 to June 2014).
The existing wave-based weights have already been adjusted for non-response and eligibility. This has been applied separately by wave, and then each wave was calibrated to relevant population totals.
To calculate round 5 weights, the existing wave-based weights have been joined so that each quarter has one eighth of the total weight. Each quarter has been calibrated separately to the mid-point of the round (the private household population total in March 2015). This approach will be applied to the cross-sectional household, person and non-proxy weights.
Round 6 weights
Round 6 represents the first round based on new data, in that a two-year version of the wave 6 weight will not exist. The round 5 weights will represent the starting point for the weighting of round 6, and the standard methodology can be applied to adjust these for attrition and eligibility based on which panel they join the sample from. By adapting the current weighting system, round 5 to round 6 longitudinal weights alongside the person, household and non-proxy, round 6 cross-sectional weights will be produced. The revised system will be able to handle round-based weights on an ongoing basis, that is, for round 7 onwards.
Longitudinal weighting of the survivors’ dataset
There was a conceptual challenge around how to handle the longitudinal survivor cases. The overlap between wave 1 and round 1 is shown in Figure 2.
Figure 2: Overlap between wave 1 and round 1
| 2006 | 2007 | 2008 | |||||||||
| Q1 | Q2 | Q3 | Q4 | Q1 | Q2 | Q3 | Q4 | Q1 | Q2 | Q3 | Q4 |
| Wave 1 (24 months) | Wave 2 | ||||||||||
| Round 1 (24 months) | Round 2 | ||||||||||
Source: Office for National Statistics
No data exist for the first quarter (April to June 2006) of round 1, as fieldwork did not begin until the start of the wave in July 2006. Following consultation with users, a decision was taken to provide round-based weights for longitudinal survivors weighted to the middle of round 2 population. This will allow the full round 2 to round T dataset to be analysed: all cases will have T-1 observations. The R2 to RT weights could be used for R1 to RT analysis, but only about seven-eighths of the full dataset could be used in the analysis.
Round 7 weights
The full round 6 weights represent the last time that a round crosses a wave. From round 7 the survey will be sampled on a two-year, financial year basis and the weighting will be more straightforward. The same approach can then be applied, where we build on existing weights and calibrate to the mid-point of the period of interest. There may be further revisions to the weighting strategy from round 7, as a result of the wider requirements of the Household Financial Survey.
Back to table of contents6. Wave 5 and round 5 estimates
Key wealth estimates are shown in Table 1, showing the estimates for wave 4, wave 5 and round 5 along with the standard errors attached to the estimates for round 5.
| Aggregate wealth (£ billion) | ||||||
| Wave 4 July 2012 to June 2014 | Wave 5 July 2014 to June 2016 | Round 5 April 2014 to March 2016 | Difference W5 - R5 | Standard Error Round 5 | ||
| Property Wealth (net) | 3,806 | 4,516 | 4,376 | -140 | 73 | |
| Financial Wealth (net) | 1,564 | 1,630 | 1,605 | -25 | 123 | |
| Physical Wealth | 1,130 | 1,230 | 1,215 | -15 | 11 | |
| Private Pension Wealth | 4,385 | 5,354 | 5,215 | -139 | 72 | |
| Total Wealth (including Private Pension Wealth) | 10,886 | 12,730 | 12,412 | -318 | 196 | |
| Total Wealth (excluding Private Pension Wealth) | 6,500 | 7,376 | 7,197 | -179 | 161 | |
| Median (£) | ||||||
| Wave 4 July 2012 to June 2014 | Wave 5 July 2014 to June 2016 | Round 5 April 2014 to March 2016 | Difference W5 - R5 | Standard Error Round 5 | ||
| Property Wealth (net), (households with property ownership only) | 152,000 | 175,000 | 170,000 | -5,000 | 1,800 | |
| Financial Wealth (net), (all households) | 5,900 | 6,200 | 6,200 | 0 | 200 | |
| Private Pension Wealth, (households with pension wealth only) | 96,800 | 114,800 | 111,500 | -3,300 | 2,300 | |
| Total Wealth (including Private Pension Wealth) | 223,100 | 262,400 | 254,100 | -8,300 | 4,800 | |
| Total Wealth (excluding Private Pension Wealth) | 140,000 | 156,300 | 154,200 | -2,100 | 2,600 | |
| Mean (£) | ||||||
| Wave 4 July 2012 to June 2014 | Wave 5 July 2014 to June 2016 | Round 5 April 2014 to March 2016 | Difference W5 - R5 | Standard Error Round 5 | ||
| Physical Wealth (all households) | 44,900 | 48,400 | 47,700 | -700 | 500 | |
Download this table Table 1: Main wealth estimates and standard errors
.xls .csvWealth estimates from WAS are reported on a nominal basis, that is, not adjusted for inflation. As round 5 covers a period that begins and ends three months earlier than wave 5, it might be expected the estimates for round 5 are marginally lower than their wave 5 equivalents. This is reflected in the figures in Table 1 and is also true for the majority of other round 5 estimates shown in the detailed datasets. There may be more fluctuation where estimates are based on lower numbers of survey responses. However, none of these differences are statistically significant.
Back to table of contents