In this section
- Introduction
- An Administrative Data Census approach for producing population and household outputs
- Things you need to know about this release
- Different challenges for different topics and variables
- Methodology for population and household characteristics
- How we’ll validate and measure the quality of outputs from an Administrative Data Census
- Summary
- Appendix A: Two Small Area Estimation methods
1. Introduction
The Office for National Statistics (ONS) Census Transformation Programme recently published its Annual assessment of progress towards an Administrative Data Census post 2021. The assessment explains what we mean by an Administrative Data Census and uses a set of evaluation criteria to assess our ability to move to one in the next decade. It describes our progress in gaining access to data sources, our ability to link data, and other criteria that we'll need to meet.
Following a public consultation in 2013 about producing census-type outputs, users told us an administrative data-based approach to conducting a census would need statistical methodologies that could:
- provide robust estimates about the size of the population and the number of households
- provide estimates about population characteristics at a point in time to allow similar areas to be compared
- provide information for local areas and measure change over time (for example, being able to measure changes in unemployment rates by ethnicity for small geographical areas)
To move to an Administrative Data Census that meets these requirements, we'll need to combine a number of different types of data sources to produce cross-tabulated, small area outputs.
This report sets out the basis for future research into how we'll produce outputs for population characteristics (such as population by employment status and ethnic group) from an Administrative Data Census. We've published details of the methods used to produce estimates of the size of the population and number of occupied addresses ("households") alongside the Administrative Data Census Research Outputs.
Back to table of contents2. An Administrative Data Census approach for producing population and household outputs
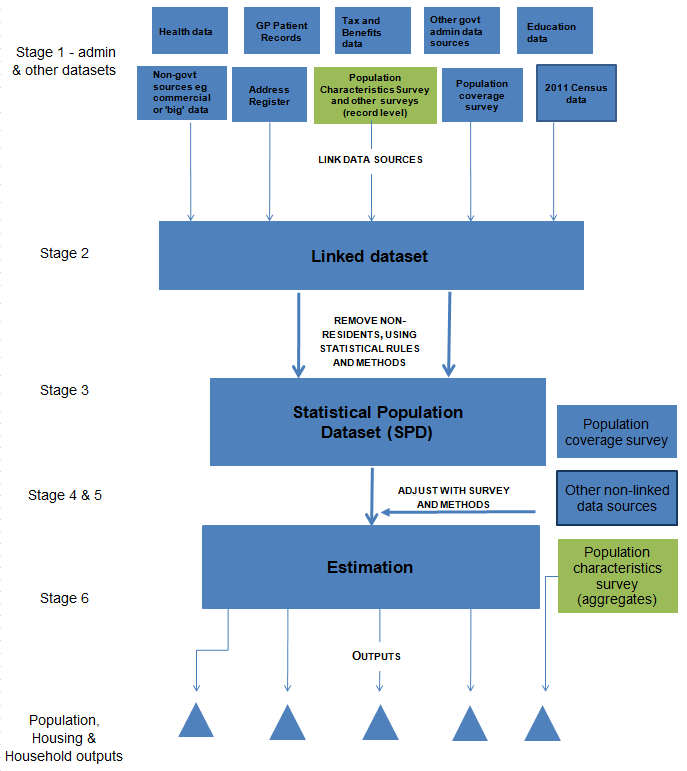
n the stages detailed in this section, we have described a plan for producing population outputs for an Administrative Data Census. This is also shown in Figure 1. This builds on the framework for estimating the size of the population that we published in 2014, and has been extended to include outputs about the characteristics of the population and housing.
Stage 1: Evaluate the quality and integrity of the administrative, survey and other data sources individually.
Stage 2: Link data sources at record level whilst preserving privacy.
Stage 3: Construct a Statistical Population Dataset (SPD) through a set of "rules" to determine which records and/or matches from the linked dataset are included in the usually resident population1.
Stage 4: Carry out a Population Coverage Survey (PCS) designed to measure both the under- and over-coverage of the SPD.
Stage 5: Carry out a Population Characteristics Survey (PChS) designed to collect priority information on characteristics of the population, households and housing.
Stage 6: Produce estimates of the usually resident population by age, sex and geographical area and number of households. Information collected in the PChS will be combined with the SPD to produce census-type outputs on the characteristics of the population and housing.
The main addition to the 2014 framework is the wider range of administrative sources and the annual PChS. Our current assumption is that this large-scale survey would cover approximately 4% of the population (around 900,000 households) each year. It would need to collect information on the priority characteristics of the population, households and housing.
The PChS would be needed to support administrative data to produce a range of small area cross-tabulated outputs on these characteristics of the population. The exact design of this survey will depend on our access to administrative data and an understanding of their statistical quality.
Figure 1: Framework for producing Administrative Data Census outputs by combing data sources
Source: Office for National Statistics
Download this image Figure 1: Framework for producing Administrative Data Census outputs by combing data sources
.PNG (35.2 kB)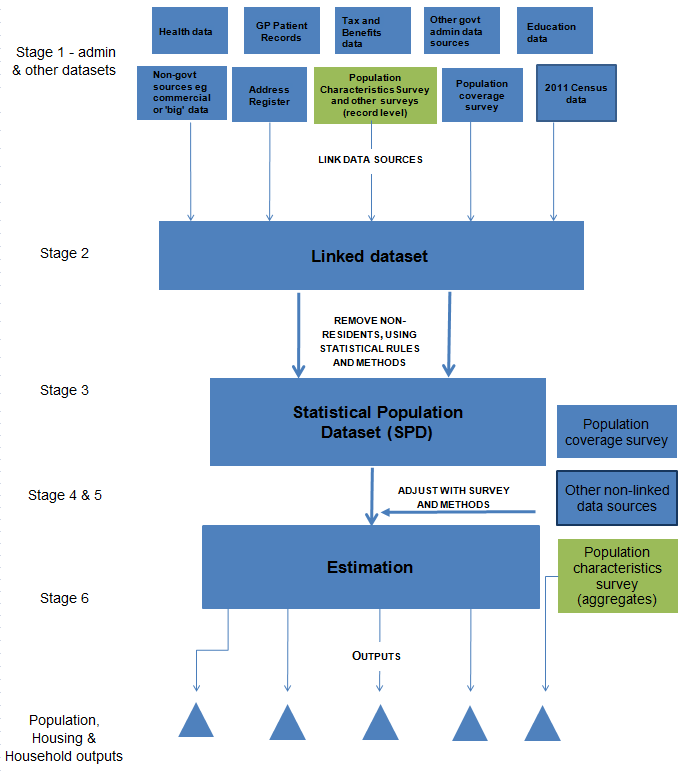{kind=link}
Notes for: An Administrative Data Census approach for producing population and household outputs
- The definition of "usually resident population" is people who reside, or intend to reside, in the country for at least 12 months, whatever their nationality. This is consistent with the standard UN definition for population estimates.
3. Things you need to know about this release
The rest of this report summarises our initial work on how we can combine administrative, survey and other data sources to produce outputs for population characteristics from an Administrative Data Census.
We recognise this will need a large Population Characteristics Survey (PChS), as the administrative data won't provide all the information needed. However, we'll also need to consider different approaches for combining the administrative, survey and other data sources to produce robust population outputs. Through the approach taken and methods used for the Administrative Data Census, we can also show how 2021 Census outputs could be enhanced by combining census data with other sources.
The report focuses initially on producing univariate outputs at the lowest geographic level possible. Where possible, we aim to produce outputs directly from administrative data, but will draw strength from survey data and other sources when needed. We'll need to do further methodological work to address the user need to create full multivariate outputs.
The report explains some of the challenges of using administrative data to produce census-type outputs. We present some scenarios showing how the type and quality of data sources available for estimating population and household characteristics vary, taking into account issues with coverage and other dimensions of quality. We then describe some examples of appropriate statistical methods that may be applied to overcome the challenges in each scenario. We'd like your ideas on other methods that might be appropriate for further research in this area.
Please contact us via email at Admin.Data.Census.Project@ons.gov.uk.
In this report:
- "characteristics" or "variables" are outputs (similar to census outputs) that we plan to estimate using administrative and survey data; for example, "highest level of qualification", "place of study" or "ethnicity"
- "census topics" refer to the broad categories of characteristics such as "health" or "education"
The next section of the report sets out the different challenges around producing census-type outputs from administrative data sources.
Back to table of contents4. Different challenges for different topics and variables
The factors affecting our ability to produce outputs for each census topic from administrative data will vary and are detailed further in this section.
4.1 Variable factors
The information about these topics that's available from administrative data
This information includes:
- the number of sources
- how well they cover the resident population
- whether the definition meets user requirements (relevance)
- whether relationships between the sources exist
- how well they measure the topic of interest (accuracy)
The extent to which the variable stays the same or changes over time
For example, a person's place of birth doesn't change, whereas a person may change their marital or health status.
The stability and comparability of a variable over time
While geographical location of birth wouldn't change, country of birth might change due to movement of borders or the renaming of the country.
The number of people with a given characteristic within a population (prevalence)
For example, ethnic group categories aren't evenly distributed in England and Wales. There is a far greater number of people in the white category than any other group.
The distribution of the people or households with a given characteristic across geographies and across other population sub-groups
For example, London households generally have accommodation with fewer bedrooms than households in the north of England.
The matching accuracy when linking data sources
Some characteristics will need multiple data sources to be linked. Matching individual records across multiple sources can introduce error due to differences in coverage, accuracy and variable definition of the data sources.
4.2 Addressing the challenges
Most census topics won't be accurately measured with one administrative data source, but are likely to be partially represented in a number of different sources. Different approaches and methods will be needed to combine information and draw strength from a range of sources. Where there's little or no coverage of a topic in administrative data, the alternative is to produce survey estimates at an aggregate level.
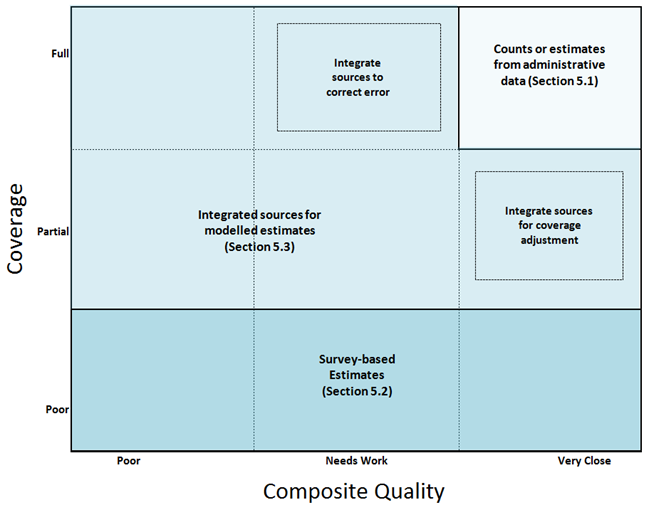
Our annual assessment included a brief analysis of the coverage and quality of important census population and housing characteristics in administrative data sources (Figure 2).
The composite quality measure shows how close the definition of the data is to what's needed by users. It also shows whether there's a known error in the data. More information about how we evaluate the quality of data is available in the annual assessment.
Figure 2: Quality assessment of administrative sources

Source: Office for National Statistics
Download this image Figure 2: Quality assessment of administrative sources
.PNG (185.8 kB){kind=link}
Some data collected in the census aren't currently available in administrative sources we have access to. Plus, surveys alone won't provide the detail that users need to measure change over time at small area levels. To overcome this and produce outputs covering a range of population characteristics similar to a census, we'll need access to more administrative data.
The Digital Economy Act 2017 gives the UK Statistics Authority a statutory right of access to information held by government departments, other public bodies, charities, and large and medium-sized businesses, for statistics and research purposes. This will help make sure we have access to more data and allow us to make progress towards producing fit-for-purpose statistics.
The next section introduces methods that might be used to produce census-type outputs depending on the administrative data available.
Back to table of contents5. Methodology for population and household characteristics
Based on our current assessment, population and household characteristics have varying levels of coverage and quality in administrative data (as outlined in Figure 2). This means we'll need to use various different approaches required to produce fit-for-purpose estimates.
Figure 3 indicates how the coverage and quality of administrative data sources may affect the type of methods used to estimate population and household characteristics.
There are a number of different scenarios for variables in this framework depending on the structure and distribution of the variable, as well as the number, type and statistical quality of administrative data sources available. Some of these scenarios are outlined in this section with examples of existing methods we use to address the challenges. We begin by explaining the simpler scenarios, where we have administrative data that accurately capture a characteristic or where there are little or no administrative data. We then introduce more complex examples such as where we need to combine sources or use modelling approaches.
We intend to add further scenarios and develop alternative methodological solutions as we continue to explore different characteristics and data sources, working with the academic community and other national statistics institutions.
Figure 3: Coverage and quality of administrative data for (individual) population and household characteristics: implications for methods
Source: Office for National Statistics
Download this image Figure 3: Coverage and quality of administrative data for (individual) population and household characteristics: implications for methods
.PNG (76.8 kB)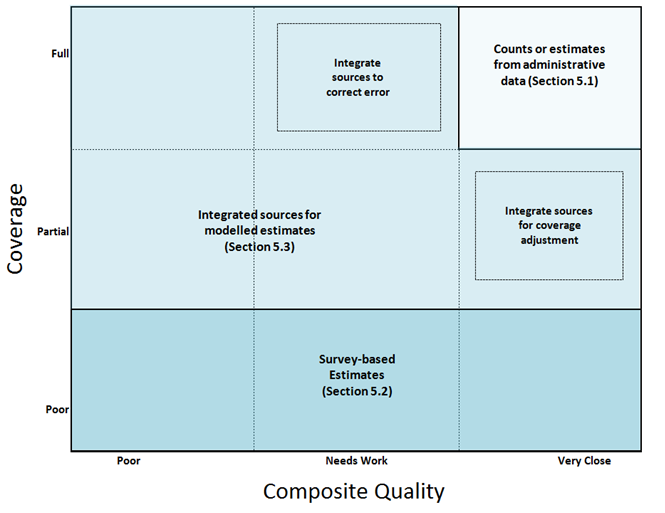{kind=link}
5.1 The variable is accurately captured in an administrative source
It may be that the variable is accurately represented in the administrative data (light shaded area in the top-right of Figure 3). In these cases, we anticipate estimates can be produced more directly by summing counts of individuals or households for the resident population within the required sub-groups at the relevant geography.
As for any outputs, there needs to be a full evaluation of the quality of the administrative data against clear standards to ensure the estimates are accurate. See Section 6 for more information on this.
We expect to make only limited use of survey or other data sources to support and ensure the quality of these estimates. A possible example is the "number of bedrooms" characteristic, which can be found in Valuation Office Agency (VOA) administrative data. We're still exploring the VOA as a data source and you can read about our early findings in Estimating the number of rooms and bedrooms in the 2021 Census: An alternative approach using VOA data.
5.2 The information in administrative data has very poor coverage or there's no information available for the characteristic
There will be some outputs traditionally provided by a census that can't be obtained from administrative data. These include, for example, subjective measures such as a person's general level of health. In this case, we expect that estimates would mostly be based on survey data (dark shaded area at the bottom of Figure 3).
We currently carry out various annual surveys that provide aggregate-level estimates for many census outputs between census years. Historically, the surveys have obtained samples that provide estimates at higher geographical levels, for example, national or regional estimates.
The Annual Population Survey (APS) is currently the largest survey in England and Wales, and includes approximately 320,000 participants every year. It can be used to produce estimates for population characteristics at regional level and for some characteristics at local authority level.
It hasn't been considered economically viable to have survey samples large enough to obtain robust estimates for very small geographies (for example, below local authority level) or for very detailed population sub-groups (where sample counts may be small or contain no sample). For an Administrative Data Census, we need to understand how best to produce robust estimates for small geographies and detailed population sub-groups (including cross tabulations that measure change over time) when there's no information available in administrative sources to support estimation models.
We intend to develop and design a large-scale annual Population Characteristics Survey to support the Administrative Data Census outputs, as shown in Figure 1. Our current assumption is that it will cover 4% of the population (around 900,000 households) each year and will collect information on priority characteristics. The exact design will depend on our access to administrative data and the quality of the data.
5.3 Administrative data sources are available but the coverage and/or quality aren't of an appropriate standard to produce direct counts
We expect the majority of our outputs to be produced using a combination of administrative and survey data. Different scenarios about the quality and coverage of administrative data are presented in sections 5.3.1 and 5.3.2, and as set out in Figure 3. We refer to methodological approaches that may be used to address these different challenges.
5.3.1. The quality of administrative sources
Imputing values for missing data
If the administrative data captures the variable of interest but there's a relatively small number of missing values, traditional edit and imputation (E&I) methodology may provide a suitable statistical framework for estimating these values. E&I methodology can also be used to resolve logical inconsistencies in a dataset. This could be, for example, where an individual has a recorded age of only 6 years old but other variables indicate they're married and/or in full-time employment.
Our Methodology Division has developed extensive experience in E&I methods and strategies by applying them to consecutive censuses and Office for National Statistics (ONS) social and business surveys. More information about the 2011 Census imputation strategy can be found in the 2011 Census: Methods and Quality Report. For a general overview of statistical E&I methodology, see the Handbook of Statistical Data Editing and Imputation (De Waal, Pannekoek, and Scholtus, 2011).
In considering these methods for an Administrative Data Census, it's important to understand how statistical assumptions associated with applying E&I methodology to a traditional survey translate to the E&I of linked administrative data. In any circumstance, an E&I method applied inappropriately can very easily introduce additional bias or error into survey estimates. Traditional methodological assumptions include the randomness of missing or inconsistent data values.
In an Administrative Data Census the quality of the administrative data source and the effect of uncertainty associated with the accuracy of the linkage mechanism will also be important factors. Understanding these factors and how they relate to each other will be particularly important when linking several administrative sources to achieve multivariate outputs.
To meet the challenge of an Administrative Data Census, the ONS Methodology Division is investing in understanding the relationship between traditional E&I methodology and the aim to use more administrative data in statistical estimates. For example, a recent research programme has demonstrated that linked administrative data can be used as auxiliary information to improve the accuracy of the E&I methodology used to impute missing age in census data. The results of this study will be published in due course.
Exploratory work is also underway to examine the use of E&I methodology to estimate missing values in linked census-administrative data where the administrative data source has been used to replace traditional census questions. All of this work is being supported through an E&I working group with links to academics, statisticians, stakeholders, and other national statistical institutions.
Correcting measurement error
There may be a situation where there's good coverage in the administrative source but there are measurement errors. It may be possible to use a model to define the structure of the error and then use the information obtained from the model to apply corrections. This requires the Population Characteristics Survey (PChS) to be accurately linked to the administrative data.
We plan to investigate potential methods for an Administrative Data Census.
Integrating sources with model-based estimates to overcome definitional differences
For some population or household characteristics, the information available in administrative sources may be similar to, but defined differently from, the characteristic required. The data may represent a different population characteristic but be related (correlated) with the variable of interest. Alternatively, the data may have the same category structure but be defined in a different way to the variable of interest.
We've previously used Small Area Estimation (regression) models and Generalised Structure Preserving Estimators (GSPREE) to combine information from administrative data with estimates obtained from surveys. This was to produce statistical estimates at an aggregate level that wouldn't be possible by using each source on its own.
We've recently used the GSPREE methods to produce ethnic group population estimates at local authority level. This involved using distributions from school census data and adjusting these according to information on ethnicity available in the Annual Population Survey (see Appendix A for more information on the model-based estimation methods).
Both regression and GSPREE methods are model-based. They provide a proven statistical framework for combining information available in administrative sources (that are related to the characteristic of interest) by relating them to survey estimates for the characteristic. They're flexible because data sources can be included as they become available or excluded if they're no longer appropriate.
The methods also provide information about the contribution of each individual source in the estimation process. This could be used to understand the relative importance of the different sources whilst moving from outputs based on a 10-yearly census to those based on administrative sources. An advantage of this method is that variance, or error in the estimates, can be measured, which provides an indicator of the quality of the outputs.
Enhancing survey estimates with administrative data
In some cases, we may want to use administrative data to enhance survey-based estimates instead of using surveys to enhance administrative data.
We've previously used model-based, Small Area Estimation techniques to improve the precision of survey estimates for small geographical areas or detailed population sub-groups where sample counts are too small to derive estimates directly from the survey data. For example, small area regression models are used to derive local authority estimates of unemployment.
As described previously, these methods draw strength across different data sources and across similar areas or population sub-groups. They may be used to produce estimates for some characteristics in an Administrative Data Census (probably at an aggregate level) where the variable of interest can't be obtained directly from administrative data.
However, the methods need strong supporting information (correlates) to be available in the administrative sources that relate to the variable of interest. They also need a statistical model that's appropriate for the data and type of output.
Using surveys to correct bias
Structure Preserving Estimation (SPREE), which is a simple case of GSPREE, can also be used to correct inaccuracies in estimates of population characteristics derived from administrative data. We've applied these methods to improve the accuracy of estimates of household size, using information available in the Annual Population Survey combined with administrative data.
The SPREE methods adjust the distributions obtained from the administrative sources to the aggregate (or higher level) totals shown in the survey data.
5.3.2. The coverage of administrative data
Use of coverage surveys
There may be cases when the quality of administrative data is good but doesn't include the entire population that the estimates are based on. Alternatively, it may include people who aren't part of the population. In these situations, survey data can help us to correct for these coverage errors.
We plan to investigate the potential of using Administrative Data Census surveys for adjusting administrative data estimates of population characteristics. We'll need to develop methods to adjust estimates for both under- and over-coverage.
Combining administrative sources
It may be that administrative data cover the resident population well but capture information for only a component (but not all) of the variable of interest and additional sources cover a different component. In this case, the sources could be linked to provide the full information requirements.
For example, the Administrative Data Census Research Outputs on income for year ending 2014 combine information from various components of income to produce an estimate of individual gross (total) annual income. The income information combined includes:
- gross earnings through Pay-As-You-Earn (PAYE)
- state support and most benefits (from the Department for Work and Pensions)
- tax credits (from HM Revenue and Customs)
- income from occupational and personal pensions (PAYE)
Some income components (for example, income from self-employment) aren't currently covered in the Research Outputs. These components will be added once the new datasets become available.
More generally, we're considering:
- the quality of the linkage of data sources
- the coherence between the sources if they were collected at different time points
- where appropriate, how we can create household estimates from information provided about individuals
6. How we’ll validate and measure the quality of outputs from an Administrative Data Census
One of the main challenges when using administrative data, and integrating it with other data sources, is how to measure the quality of the outputs. Output quality depends on:
- the quality of the data
- the accuracy by which the sources can be linked
- good relationships existing between data sources that allow us to create statistical models that draw strength across all the relevant and available information
Appropriate methods are required for each output.
So far, Administrative Data Census outputs have been validated against existing outputs from the recent census and other official estimates. In 2021, Administrative Data Census outputs will be produced alongside, and compared with, the 2021 Census estimates. This is so we can validate the feasibility of moving to an Administrative Data Census after 2021.
We'll need to estimate uncertainty in the outputs that are derived from multiple (administrative and survey) sources. This is so we can provide information about their quality and to allow the estimates to be appropriately compared with external population sources.
We'll need to develop methods that take into account the different sources of error across the data sources (including coverage and measurement error in administrative sources and sampling error in surveys), as well as any uncertainty in assumptions made when integrating sources for estimation.
We're now developing the methods used for the Measures of Statistical Uncertainty accompanying our mid-year population estimates (currently published as National Statistics). This is to create measures of statistical uncertainty for the new population estimates derived from the Statistical Population Dataset (SPD).
The methods take into account the potential sources of error across the data sources and methods used. They apply simulation techniques to derive measures of statistical uncertainty associated with the estimates. This work is currently at an early stage but could potentially be adapted for administrative data-based population characteristics.
Eventually, we'd like outputs to move from Experimental Statistics to National Statistics status. To accomplish this, there needs to be a full evaluation of the quality of the administrative data against clear standards to ensure the estimates are accurate. The regulatory standards in the Office for Statistics Regulation's toolkit ensure the outputs based on administrative sources meet the requirements for National Statistics defined by the UK Statistics Authority.
Finally, with the Small Area Estimation model-based approaches, measures of error (including confidence intervals) can be produced for the estimates. These, along with direct survey estimates, could be used for benchmarking the estimates from direct administrative sources. We'll also continue to invite users to provide feedback on the methods and data used in our Research Outputs, in addition to feedback on the outputs themselves.
Back to table of contents7. Summary
Our ambition is to produce a Statistical Population Dataset from linked administrative data (supported by survey data) that:
- includes information about population characteristics
- enables a flexible way to produce aggregate cross-tabulated estimates
Ideally, we'd achieve this by linking administrative data and producing direct counts for the variable of interest. However, many variables may not be accurately represented or available in the data. Alternatively, the information may only be partially relevant or cover part of the usually resident population.
The Digital Economy Act 2017 will facilitate access to more administrative data. However, for some characteristics it will be necessary to combine information from a range of sources to derive outputs at an aggregate level using appropriate estimation methods.
This report has set out a number of different approaches that could be adopted to address this challenge. It sets the foundation for future research in this area, which will also need to consider the production of multivariate outputs.
The strategy is to initially focus on producing univariate outputs at the lowest geographic level possible (using data and methods available). We'll continue testing these in the development of our Research Outputs. We'll extend these outputs to include both unit and aggregate level, multivariate outputs. These will focus on what can be produced directly from administrative data and from model-based approaches using integrated sources.
Alongside this, we'll also need to develop methods to gauge uncertainty in the estimates that are derived from combining a range of sources to provide information about the quality of Administrative Data Census Research Outputs. We'll need to develop methods that take into account the different sources of error across the data sources as well as any uncertainty in assumptions made when integrating sources for estimation.
Back to table of contents8. Appendix A: Two Small Area Estimation methods
This section provides further information about two Small Area Estimation methods. These might be used to produce Administrative Data Census outputs about population or household characteristics when the information available in administrative sources is related to, but not the same as, the characteristic required. Such models can be designed to make use of a variety of relationships across time, geography and other population characteristics. These include:
- a model-based regression approach
- a model-based structural approach
A.1 Regression model-based Small Area Estimation
The Small Area Estimation (regression) models have previously been used to overcome the problem of small sample counts when deriving survey estimates for small geographical areas.
The approach involves identifying a model that relates the survey variable of interest (such as unemployment) to the other supporting variables that are related (correlated) to it. Information (the parameters) from the models can then be used to produce robust estimates even for areas where there are few survey counts or for areas that weren't sampled.
Small Area Estimation regression methods work by drawing strength from information across data sources for other supporting variables related (correlated) to the variable of interest. For example, the local authority estimates of unemployment we produced combine information on unemployment from the Labour Force Survey (LFS) with information on unemployment benefit claimant counts from the Department for Work and Pensions (DWP).
As those who are unemployed form a small percentage of the population, the LFS local authority estimates are based on very small samples and are therefore unreliable in many areas. Model-based estimates improve the LFS estimate by borrowing strength from the claimant count to produce an estimate that is more precise. The claimant count isn't itself a measure of unemployment but is strongly correlated with unemployment. Further information is available in the Model-based estimates of International Labour Organisation unemployment for local authority districts and unitary authorities in Great Britain: guide for users.
For the Administrative Data Census, Small Area Estimation (regression) models could be useful when there's information in administrative data that's related (or distributed in a similar way) to the characteristic being estimated but direct information isn't available.
A.2 Generalised Structure Preserving Estimation
Generalised Structure Preserving Estimation (GSPREE) combines information available in administrative or other sources with survey data to improve the quality of estimates for cells within a cross tabulation. The approach has previously been applied to update the census tables for local authority population by broad ethnic group. This is where the information available in survey and administrative sources has the same category structure as the characteristic being estimated. Research Outputs from this are also available.
Figure 4: Structural representation of data for estimating 2014 population by local authority and ethnicity using GSPREE model based approach
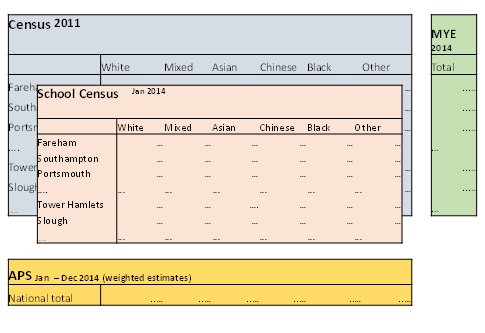
Source: Office for National Statistics
Download this image Figure 4: Structural representation of data for estimating 2014 population by local authority and ethnicity using GSPREE model based approach
.PNG (12.1 kB)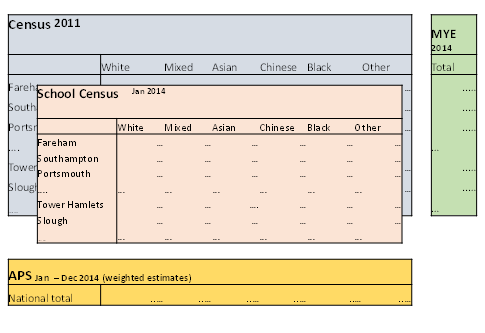{kind=link}
This approach obtains a best estimate of the structure of the cross-tabulated cells using a model that relates the survey counts to the counts in the supporting data sources (that have the same structure but a different definition or reference date to that required).
In this example, local authority estimates by ethnic group are required for 2014. However, the detailed census information for the cross-tabulation is out of date and the school census data are for age groups 5 to 15 years only.
GSPREE takes these data sources and relates them to recent survey data. The Annual Population Survey (APS) data will provide information for the cross tabulation, but there may be small sample counts. The relationship between them is then used to adjust or update the cross tabulations of the census and the school census. This results in a complete table of estimated cell counts for the target time period and variable.
The method then benchmarks the estimated cell counts for the estimated cross tabulation structure to robust aggregate totals from a survey and an official source. Further information about the method and application is available in the methodology paper Assessing the Generalised Structure Preserving Estimator Population Estimates by Ethnic Group.
For the Administrative Data Census, GSPREE could be useful when there is information in administrative data that has the same category structure to the characteristic being estimated but is defined differently or covers only part of the population.
A.3 Notes about Small Area Estimation methods
Please note that these methods depend upon fitting statistical models to the data sources. The quality of the estimates for small areas depends upon the quality of these models. Each variable should therefore be explored individually based on what data are available and what level of geography is needed for output. For example, estimates of unemployment were attempted at middle layer super output area (MSOA) level but the variation in the estimates was large and therefore couldn't be relied on.
Back to table of contents