Table of contents
- Introduction
- Questionnaire design
- Sampling procedure
- Data collection
- Converting respondent data into published estimates
- Revisions policy
- Employment estimates
- The effect of different reporting periods on calendar year estimates
- Comparability of ABS estimates with other statistics
- Acknowledgements
- Annex A: Users and uses of Annual Business Survey data
- Annex B: List of Annual Business Survey questionnaire types
- Annex C: Additions and removals of Annual Business Survey questionnaires
- Annex D: Nomenclature of Units for Territorial Statistics (NUTS)
1. Introduction
This report describes the procedures used by Office for National Statistics (ONS) to produce the Annual Business Survey (ABS). The report is aimed at users who want to know more about the background and history, uses and users, and concepts and statistical methods underlying the survey. It includes information about questionnaire development, sample design, data collection, results processing, publications and quality issues.
This technical report (third edition) relates to Annual Business Survey (ABS) reference years 2016 onwards. The previous edition (second edition) relates to ABS up to the 2015 reference year. If you would like to view this version you can find it on the ABS quality and methods page.
1.1 Overview
The Annual Business Survey (ABS), formerly known as the Annual Business Inquiry – part 2 (ABI/2), is an annual survey of businesses covering the production, construction, distribution and services industries, which represents about two-thirds of the UK economy in terms of gross value added (GVA).
Every year, ABS questionnaires are sent by ONS to around 62,000 businesses in Great Britain, and by the Northern Ireland Statistics and Research Agency (NISRA) to around 11,0001 businesses in Northern Ireland.
The ABS is the largest business survey conducted by ONS in terms of the combined number of respondents and variables it covers (62,000 questionnaires despatched in Great Britain, with around 600 different questions asked). It is the main resource for understanding the detailed structure and performance of businesses across the UK and is a large contributor of business information to the UK National Accounts.
The ABS provides a number of high-level indicators of economic activity such as the total value of sales and work completed by businesses, the value of purchases of goods, materials and services, and total employment costs.
The contribution of different industries to the overall value of economic activity can be assessed and by combining ABS with employment information from the Business Register and Employment Survey (BRES), it is also possible to get a measure of value added and costs per head to allow better comparison between industrial sectors of different sizes. The indicators in the ABS publications are collected and presented as monetary values or counts, for example, approximate gross value added (aGVA), numbers of enterprises. They are essentially a snapshot of UK business activity and can be used to understand the level of the contributions to the UK economy from different sectors of the economy at any one time. The statistics produced are referred to as structural business statistics.
ABS outputs may be used to answer questions such as:
how much wealth has been created in a particular industry?
has there been a shift in activity from one industrial sector to another, and which industry groups, classes or sub-classes are driving the change?
are any industries particularly dominant in specific regions or countries of the UK and are there structural changes over time?
how productive is a particular industry, such as the chemicals sector, and what is its operating profitability?
1.2 Main users and uses of the data
There are a wide range of users that view, download and use the ABS data. Users include those from government, both internal within ONS and external in other government departments, such as the Department for Business, Energy and Industrial Strategy (BEIS), the Department for Work and Pensions (DWP) and the Department for the Environment, Food and Rural Affairs (DEFRA). Devolved administrations such as the Scottish and Welsh Governments, as well as local authorities, also constitute main users of the ABS outputs. For government users, the ABS data are commonly used to inform policy and legislation. ABS Government User Group meetings are held biannually to give an opportunity for any changes or developments to the ABS to be discussed directly with its government users, in order that, where possible, their requirements can be met.
As mentioned in Section 1.1, the ABS output is an important contributor to the UK National and Regional Accounts to inform, for example, the estimation of gross domestic product (GDP).
On an international level, the ABS data are required by Eurostat to meet the Structural Business Statistics Regulation (SBSR) for annual structural statistics and are used to inform and monitor European Union policy.
The ABS also has a large number of non-government users, such as researchers, academics, think tanks, businesses, industry experts and the media. These users have largely been identified through internet searches, data requests and telephone queries. The uses to which the data are put are vast and varied, and the ABS team are striving to engage with these users more effectively to better understand their specific needs. In order to facilitate this engagement, the Business and Trade Statistics Community on the StatsUserNet forum was established.
Annex A contains a more detailed list of ABS users, including those mentioned previously, and lists examples of the uses to which the ABS data are put.
1.3 Publication of the Annual Business Survey results
Publication of the ABS results follows the cycle described in this section (from 2016 reference year onwards):
November – Provisional national results (for previous calendar year)
April or May – Revised national results (including revision of the previous survey year)
April or May – Revised regional results (including revision of the previous survey year)
Publications of the ABS results are available on the ABS release page and earlier releases of the Annual Business Inquiry data are available on the ABI release page.
The survey process from sample selection through to the publication of the final ABS regional results is summarised in this section. It also outlines where important information for each stage of the survey process is covered within the sections of this technical report.
Summary of the survey process
November to December – sample selection (Section 3)
January to February – questionnaires despatched (Section 4)
March to December – editing and validation (Section 5.1)
August to September – imputation, expansion, estimation, outliers (Sections 5.2 to 5.5)
October – regional apportionment (Section 5.8)
November to February – post-results processing validation (Section 5.6)
November – standard errors, disclosure control, final quality assurance (Sections 5.7,5.9 and 5.10)
November – publication: national provisional results
April to May – standard errors, disclosure control, final quality assurance (Sections 5.7,5.9 and 5.10)
April or May – publication: national final results
April or May – publication: regional final results
1.4 History
Collection of information on UK business dates back to the formation of the Board of Trade (the forerunner of the modern Department for Business, Energy and Industrial Strategy) in 1786. In 1832, the Board of Trade created its own statistics department and began a statistical yearbook, which included information on commercial activities and trade.
Figure 1 shows the number of questionnaires sent out by the Census of Production between 1930 and 1998. The number dropped significantly in the 1950s, when sampling methods were introduced. A census was still carried out every four or five years, but the threshold for inclusion in the census was raised, so the peaks representing census years between 1950 and 1970 are substantially reduced compared with 1948.
Figure 1: Number of questionnaires despatched by the census of production between 1930 and 1998
UK
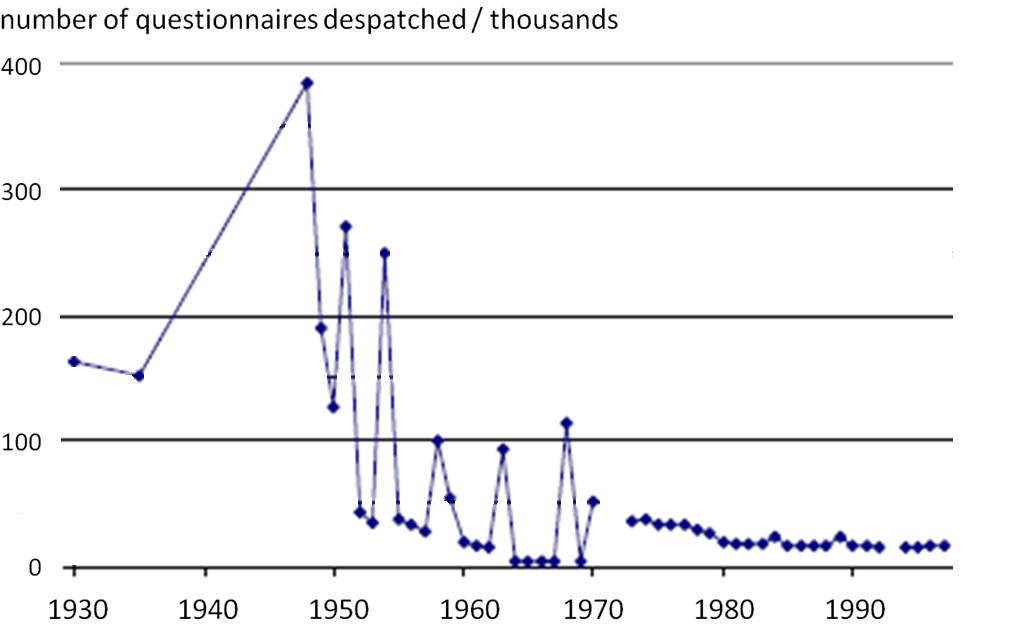
Source: Census of Production
Download this image Figure 1: Number of questionnaires despatched by the census of production between 1930 and 1998
.png (102.9 kB)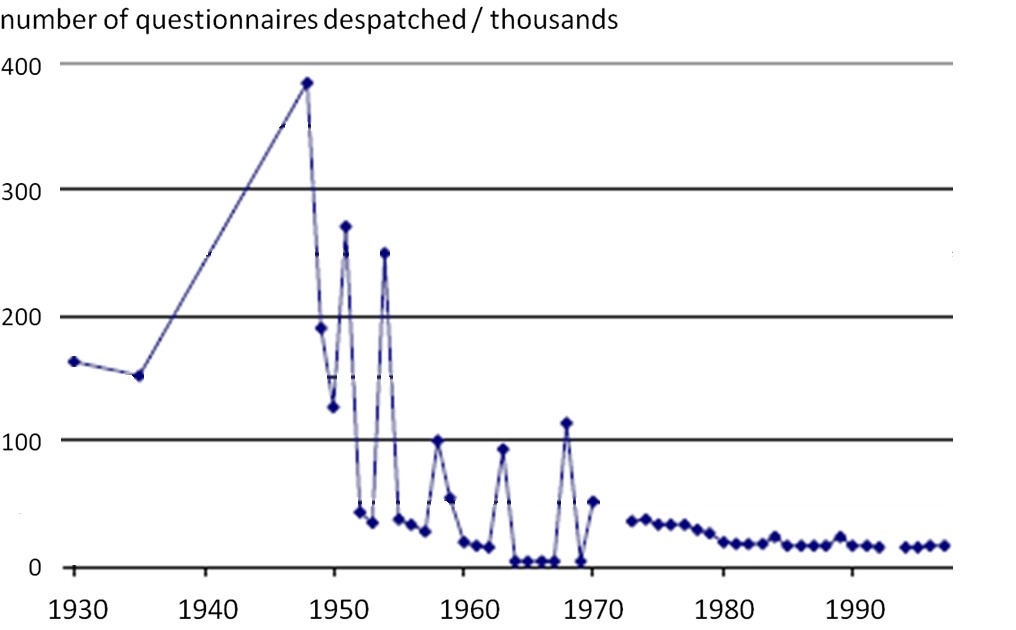{kind=link}
As sampling methods were improved, a level was approached in the 1980s beyond which it became difficult to make further significant cuts in the sample size without affecting the quality of the estimates produced. However, ONS continues to pursue methodological improvements, which allow further small reductions in the sample size. In addition, in 2011, we implemented a programme to explore and develop the use of administrative data, such as tax information from Her Majesty’s Revenue and Customs (HMRC), as an alternative or supplement to survey data.
Table 1 shows the important events in the development of the Annual Business Survey, from the first Census of Production in 1907 to the creation of the current Annual Business Survey in 2009. The table includes information on the drivers for change over these years.
Table 1: Important events in the development of the Annual Business Survey
| Year | Label | Description | Development type | |||
|---|---|---|---|---|---|---|
| 1906 | Census of Production Act | The Census of Production is introduced to set trade tariffs, by comparing production rates with imports. There is much talk about confidentiality and burden on businesses and whether this represents an attack on liberty or a public good. | Legislation | |||
| 1907 | First Census of Production (CoP) | The first CoP, run by the Board of Trade, is carried out. | Survey developments | |||
| 1912 | First measure of GDP (output) published | The first measure of gross domestic product (GDP) (output) is published. | Wider developments | |||
| 1930 | Agriculture and forestry excluded from CoP | Agriculture and forestry are excluded from the CoP. | Methodology | |||
| 1941 | Central Statistical Office created by Winston Churchill | The Central Statistical Office is created by Prime Minister Winston Churchill, to inform the war effort and to develop national income accounts. | Wider developments | |||
| 1947 | Statistics of Trade Act | The Act makes it a legal requirement that a Census of Production is held annually. | Legislation | |||
| 1948 | Companies Act - defines an enterprise | The Act includes the legal definition of an enterprise (one or more firms under common ownership or control). | Legislation | |||
| 1948 | Standard Industrial Classifications introduced | The Standard Industrial Classification (SIC) system is introduced and the first full post-war Census is held. | Methodology | |||
| 1949 | Northern Ireland information published alongside Great Britain | Information from Northern Ireland is published alongside that of Great Britain for the first time. | Wider developments | |||
| 1950 | First Census of Distribution (CoD) | The first Census of Distribution (CoD) is carried out, and subsequent CoDs are roughly quinquennial. | Survey developments | |||
| 1952 | Sampling methods introduced | Sampling methods are introduced. The largest businesses are completely enumerated, 1 in 10 of businesses employing fewer than 11 people are selected, and the same sampling fraction is used for businesses of the same size for every industry, except where this would generate very large samples. This approach was used until 1993. The sampling frame becomes important, and is based on the response to the 1950 Census. The census continues to be held every four years, with sample surveys in intervening years. | Methodology | |||
| 1954 | Verdon Smith report published | The Verdon Smith report is published. This confirms the need for a census, but noted that businesses themselves did not in general find the results useful. | Wider developments | |||
| 1958 | SIC 1958 | The reviewed classification system reduced the scope of manufacturing, including the omission of production and processing of cinematographic films, and bakehouses attached to retail shops. | Methodology | |||
| 1958 | Five-yearly census reintroduced, with sample surveys in intervening years | A five-yearly census is reintroduced, with sample surveys in intervening years; sample surveys used as input to national accounts, and to revise estimates from short-period surveys. | Methodology | |||
| 1963 | Fully computerised system introduced | The first fully computerised system is introduced. Punched cards and an electronic calculator had been in use since 1955. The business register is stored on magnetic tape. | Wider developments | |||
| 1968 | SIC 1968 | Some industries are added in the review, for example, coffee blending grinding and roasting, and tea blending. Some industries are dropped. | Methodology | |||
| 1968 | GSS established | The Government Statistical Service (GSS) is established by Claus, now Lord, Moser. | Wider developments | |||
| 1969 | Business Statistics Office created | The Business Statistics Office is created. | Wider developments | |||
| 1970 | CoP becomes annual - renamed ACoP | The Census of Production becomes annual and is renamed the Annual Census of Production (ACoP) | Survey developments | |||
| 1970 | Census of Employment (CoE) is introduced | The Census of Employment (CoE) begins, as National Insurance cards are discontinued. National Insurance cards, introduced in 1911, were held by businesses and swapped at labour exchanges, and were used to measure employment. | Survey developments | |||
| 1973 | UK joins the European Economic Community | The UK joins the European Economic Community (EEC, the "Common Market"), and comparability with European nations becomes more important. An EEC directive is issued, which coordinates annual structural surveys in EEC member states. | Wider developments | |||
| 1974 | Purchases Inquiry (PI) introduced | The first five-yearly Purchases Inquiry (PI) is carried out. | Survey developments | |||
| 1974 | Census of Construction (ACoC) introduced | The Annual Census of Construction (ACoC) is introduced. | Survey developments | |||
| 1976 | Retail inquiry is first part of ADSI to be carried out | The retail inquiry is first part of the Annual | ||||
| Distribution and Services Inquiry (ADSI) to be carried out. The need for this inquiry is driven by the growing services sector in the UK. | Survey developments | |||||
| 1978 | Sampling used more widely | Sampling is introduced more widely and now includes businesses with fewer than 50 employees. | Methodology | |||
| 1980 | SIC brought in line with European NACE classification | This review brings the UK SIC system into line with European NACE classification. | Methodology | |||
| 1980 | SIC 1980 | SIC 1980 makes changes to SIC 1968. | Methodology | |||
| 1981 | Rayner Review | The Rayner Review took the view that statistics should be produced primarily for the purposes of government. In the same year, the ACoP publication recognises that European legislation is also a driver for the production of statistics. | Legislation | |||
| 1984 | Business register introduced - based on VAT information | A business register is introduced, based on Value Added Tax (VAT) information. | Wider developments | |||
| 1986 | First questions about computers | The first questions on computers are introduced. These are on the number of employees using computers, and the costs of buying and leasing computers. | Methodology | |||
| 1989 | Transfer of Business Statistics Office to the Central Statistical Office | The Business Statistics Office is transferred to the Central Statistical Office. | Wider developments | |||
| 1991 | First questions on pollution and waste management | The first questions on pollution and waste management are introduced. | Methodology | |||
| 1992 | Breakdowns of capital expenditure and stocks dropped | Breakdowns of capital expenditure and stocks are dropped from the ACoP publication. These are now estimated from quarterly surveys. | Methodology | |||
| 1992 | Question on research and development added | Questions on research and development activity are added. | Methodology | |||
| 1993 | First revision of NACE and hence SIC | The first revision of NACE is carried out, and SIC is subsequently reviewed. | Methodology | |||
| 1993 | SIC 1992 | SIC 1992 makes changes to SIC 1980. | Methodology | |||
| 1993 | Introduction of IDBR | The Inter-Departmental Business Register (IDBR) is introduced. It integrates VAT and Pay As You Earn (PAYE) administrative data. Formerly, the sampling frame for service industries was based on a VAT register, and the one for production industries was based on an employment register. | Wider developments | |||
| 1994 | First electronic release - on CD-ROM | The first electronic publication of census data was on CD-ROM. | Wider developments | |||
| 1995 | CoE becomes AES | The Census of Employment becomes the Annual Employment Survey (AES). The sample is reduced, and the frequency increased. | Survey developments | |||
| 1996 | EU Structural Business Statistics legislation passed | EU legislation on Structural Business Statistics is passed, which set out in detail the requirements for structural business statistics, and extend the coverage to service industries. The Annual Business Inquiry (ABI) is developed in response to the legislation. | Legislation | |||
| 1996 | Office for National Statistics formed | The Office for National Statistics is formed by merging the Central Statistics Office, the Office of Population Censuses and Surveys, and the statistics division of the Department of Employment. | Wider developments | |||
| 1997 | ACoP modified | ACoP is modified. The employment variable moves to snapshot instead of average over year. The snapshot date is initially 12 December, but issues with seasonality meant it was moved to September in 2006. | Methodology | |||
| 1998 | AES becomes ABI/1 | Annual Employment Survey (AES) becomes Annual Business Inquiry part 1 (ABI/1), which focuses on employment variables. The implementation of the IDBR, EU regulation, and the need for greater efficiency drive the development of ABI. | Survey developments | |||
| 1998 | ACoP/C, ADSI, PI, combined to become ABI/2 | ACoP/C, ADSI, and PI are combined to become Annual Business Inquiry part 2 (ABI/2), which focuses on accounting variables. | Survey developments | |||
| 2000 | Statistics Commission and National Statistics established | The Statistics Commission and National Statistics are established. | Wider developments | |||
| 2003 | SIC 2003 | SIC 2003 makes minor changes to SIC 1992, including additional detail at the sub-class level together with some minor renumbering and revisions, in response to user demand. | Methodology | |||
| 2004 | Insurance industry included | Coverage is extended to insurance industries. | Methodology | |||
| 2006 | Purchase Inquiry dropped | PI is dropped from the ABI. | Survey developments | |||
| 2007 | Statistics and Registration Service Act | The Statistics and Registration Services Act is passed, to promote the quality and integrity of official statistics that serve the public good. An independent body, the UK Statistics Authority (UKSA), is created as a non-ministerial department reporting directly to Parliament. | Legislation | |||
| 2008 | SIC 2007 | SIC 2007 is a significant revision, which, amongst other things, reflects the growth of new technologies. It follows the second review of the European NACE classification system. | Methodology | |||
| 2009 | ABI/1 becomes BRES | ABI/1 becomes the Business Register and Employment Survey (BRES), to reconcile differences in timing between ABI/1 and the Annual Register Inquiry, and to reduce duplication of data collected. BRES is the annual benchmark of employment and updates the IDBR. | Survey developments | |||
| 2009 | ABS replaces ABI | The Annual Business Survey (ABS) replaces ABI/2. | Survey developments | |||
| 2011 | Selective editing introduced | SELEKT, a selective editing tool, is introduced. This increases editing efficiency and statistical quality. The tool allows those returns with the highest impact on estimates to be prioritised for editing. | Methodology | |||
| 2014 | European System of National and Regional Accounts 2010: ESA 2010 implemented | The Annual Purchases Survey is introduced by ONS in response to the regulation. New questions are added to the Annual Business Survey (ABS) to ensure compliance. | Survey developments | |||
| 2015 | Survey population expanded (INQSTOP6) | A population of solely Pay As You Earn (PAYE)-based businesses was added to the Standard Business Survey Population to improve coverage. This increased the survey population by approximately 92,000 businesses. Analysis of how this influenced ABS results can be found in the report Impact on the 2015 Annual Business Survey results resulting from changes to improving coverage of the Standard Business Population. | Methodology | |||
| 2015 | New purchases apportionment methodology introduced for 2013 regional publication | A new method for the apportionment from the reporting unit purchases to the local unit level was introduced. This was to preserve the additivity of purchases components values to the total purchases from the 2013 regional publication onwards. | Methodology | |||
| Source: Office for National Statistics | ||||||
Download this table Table 1: Important events in the development of the Annual Business Survey
.xls (54.3 kB)Notes for: Introduction
- Increasing from 9,000 for ABS 2011 to 11,000 for ABS 2012.
2. Questionnaire design
2.1 Overview
There are currently 48 different questionnaire types for the Annual Business Survey (ABS).
All questionnaires contain a number of generic questions based on templates from the Standard Services and the Standard Production questionnaires. However, with the wide range of industries covered by the ABS, there is a need for industry-specific questionnaires to collect detailed information and to ensure that respondents only receive questions that are applicable to their business area. This avoids placing unnecessary burden upon respondents in sifting through a number of questions which to them may be irrelevant. In due course, Office for National Statistics (ONS) is making a move towards online data collection, which will aid questionnaire filtering further.
The next sections describe the different questionnaire types (Section 2.2), how questionnaires are developed (Section 2.3) and the ongoing questionnaire review process (Section 2.4). Section 2.5 defines the variables published by the ABS.
2.2 Questionnaire types
A full list of the current questionnaire types is contained within Annex B, and examples are available on the ABS webpages. The 48 different questionnaires are made up of 34 “long” and 14 “short” versions. Both long and short questionnaires are despatched for most sectors, with the short requesting totals, and the corresponding long questionnaire asking for more detailed breakdowns.
Figure 2 is an example of the turnover section of the motor trades short questionnaire. It asks only for the total turnover.
Figure 2: Turnover section on motor trades short questionnaire
UK

Source: Annual Business Survey
Download this image Figure 2: Turnover section on motor trades short questionnaire
.PNG (79.5 kB){kind=link}
On the corresponding long questionnaire, a number of components of turnover are asked for, some of which are shown in Figure 3.
Figure 3: Turnover section on motor trades long questionnaire
UK

Source: Annual Business Survey
Download this image Figure 3: Turnover section on motor trades long questionnaire
.PNG (172.3 kB){kind=link}
This is a way of reducing the burden on the respondent, since not everyone will have to answer the more detailed breakdown of questions. Instead, the data from the long questionnaires are used to apportion the short questionnaire totals using a process called expansion. To view in more detail how the expansion of the short questionnaire is carried out, please refer to Section 5.3.
As larger businesses are usually in a better position to provide a detailed breakdown, they more often receive long questionnaires (see Table 2). Businesses with employment of 250 or more almost all receive long questionnaires and as they account for over half of the ABS total turnover estimate, this contributes greatly to the overall data quality.
Table 2: Approximate percentage of businesses in each employment size band receiving long questionnaires
| Employment size band | Percentage of long questionnaires despatched | |||
|---|---|---|---|---|
| 0 to 9 | 30% | |||
| 10 to 19 | 22% | |||
| 20 to 49 | 25% | |||
| 50 to 99 | 33% | |||
| 100 to 249 | 46% | |||
| 250 or more | 98% | |||
| Source: Office for National Statistics | ||||
Download this table Table 2: Approximate percentage of businesses in each employment size band receiving long questionnaires
.xls (35.8 kB)A small proportion of businesses in the largest employment size band receive a short questionnaire. This is due to bespoke size bands that are applied to the sample to take into account industry sectors that have high employment but relatively low turnover, for example, cleaning, market research. These special cases are allocated the additional employment size band 100 to 999 and receive a small proportion of short forms. When viewing these businesses within the standard employment size band structure, it leads to Table 2, which shows a long-form percentage for the largest size band being less than the 100% as would otherwise have been expected.
2.3 Questionnaire development
New questionnaire types are added when a collection requirement arises that cannot easily be incorporated by adding questions into an existing questionnaire. The tables in Annex C lists the most recent additions and removals and the reasons behind the changes.
When a new requirement arises, an existing questionnaire may be amended or a new one introduced. This decision is made on the basis of minimising burden on respondents. Altering an existing questionnaire may well have an impact for those who already receive this questionnaire, with the additional questions potentially not applying to them. This can affect quality of returns and is also considered when deciding whether to amend an existing questionnaire or to design a new one. Both routes require rigorous testing prior to implementation, which can be a lengthy process.
All requests for amendments to ABS questionnaires have to be agreed by the ABS Management Board. All requests whether from ONS or from external customers have to be fully costed and agreed, including the relevant compliance costs, that is, the costs incurred by businesses through responding to the survey. Once the ABS Management Board gives provisional agreement to any change, the required changes are then tested to ensure that responding businesses understand the proposed wordings and are able to supply the relevant information. It is only once the testing has taken place, and any resulting amendments have been made, that the final agreement of the ABS Management Board is obtained and the proposals are implemented.
2.4 Questionnaire review
There is an ongoing review process in which the large number of ABS questionnaire types are reviewed systematically.
For the 2011 ABS (despatched in January to February 2012), the long and short questionnaires for both the catering and standard services sectors were reviewed. Following initial user testing and feedback of the revised questionnaires, the next stage of the testing involved sending the new questionnaires to approximately 20% of the catering sample and 10% of the standard services sample, instead of the old versions.
Catering was selected as the old questionnaire was identified as causing respondents difficulties owing to questions that were not applicable to a large number of respondents.
The services questionnaire was chosen as it is distributed to approximately 25% of the ABS sample, which is the largest sample for any questionnaire type.
Rather than focusing on specific questions, the questionnaires were stripped of all notes and the presentation improved. The testing then aimed to establish which questions had wording that caused problems by asking the respondent what data they would provide if presented with these questions. Where the understanding was unclear, the relevant notes were replaced for the next round of testing.
An example of this is the goods, raw materials and services question, which asks for energy costs. Most respondents indicated that they would not have included petrol and diesel costs within this category as required, but would place it in the answer to the road transport services question instead. The notes now make it clear what is required.
Other issues identified include clarifying the definition of capital expenditure, whether Value Added Tax (VAT) should be included, and also finding a common definition for employment, as some include casual workers and others do not. These are issues that are likely to appear across all sectors, rather than being specific to catering and services and as such, this information will help when the remaining questionnaires are reviewed. The final report, which summarises the testing that was undertaken for catering and services and contains further information on these issues and how they were resolved, is available on the ABS quality and methods page.
Analysis was undertaken to ascertain the relative quality of the data received through the new pilot questionnaires, the results of which were used when deciding whether the sector questionnaire would be wholly replaced with the revised version. The analysis compared response rates, error rates, questionnaire completion times and the number of queries received.
Table 3: Response rates and percentage response clean (no errors) on first submission for the old and pilot catering and standard services questionnaires (as of June 2012)
| Sector | Response rate (%) | Clean on first submission (%) | ||
|---|---|---|---|---|
| Catering | Long | Old | 38.2 | 57.3 |
| Pilot | 41.6 | 62.9 | ||
| Catering | Short | Old | 36 | 70.3 |
| Pilot | 35.6 | 74.5 | ||
| Services | Long | Old | 45.2 | 63.2 |
| Pilot | 43.3 | 67.1 | ||
| Services | Short | Old | 48.8 | 74.2 |
| Pilot | 51.4 | 74.5 | ||
| Source: Office for National Statistics | ||||
Download this table Table 3: Response rates and percentage response clean (no errors) on first submission for the old and pilot catering and standard services questionnaires (as of June 2012)
.xls (36.4 kB)Table 3 shows that, as at 8 June 2012, the response rates for the pilot questionnaires were either equal to or above that of the old questionnaires in three out of the four questionnaire types. In all four cases, the new questionnaires were taken on with fewer errors than the old. This resulted in both pilot questionnaires being rolled out to 100% of the services and catering samples for the ABS 2012 survey, with the old questionnaires being discontinued.
2.5 Variables collected
This section defines the variables published by the ABS. A number of the variables that ONS publish are derived variables, made up from a number of collected variables.
Approximate gross value added (aGVA)
Approximate gross value added (aGVA) represents the amount that individual businesses, industries or sectors contribute to the economy.
Generally, this is measured by the income generated by the business, industry or sector less their intermediate consumption of goods and services used up in order to produce their output, labour costs (for example, wages and salaries) and an operating surplus (or loss). The latter is a good approximation for profits, from which the cost of capital investment, financial charges and the payment of dividends to shareholders are met.
There are differences between the approximate measure of aGVA calculated by ABS and the measure of gross value added (GVA) used in the national accounts (NA). NA carry out coverage adjustments, conceptual adjustments and coherence adjustments. The NA estimate of GVA uses inputs from a number of surveys and covers the whole UK economy. Some industry sectors are not included in the ABS.
An overview of the differences between aGVA and GVA is provided in Section 9.1, while a more detailed explanation can be found in A comparison between ABS and National Accounts measures of value added.
International trade in goods and services (Great Britain only)
Businesses in Great Britain are asked whether they have either purchased (imported) or provided (exported) goods and/or services to individuals, enterprises or other organisations based outside the UK. For services, value information is collected, while for goods only a yes or no response is asked for.
These estimates are published each November alongside the provisional ABS release in a separate publication, Annual Business Survey, Great Britain non-financial business economy: exporters and importers.
Number of enterprises
An enterprise is defined as the smallest combination of legal units, which have a certain degree of autonomy within an enterprise group. While labelled in the ABS publications as an enterprise count, the counts are actually reporting unit counts from the IDBR (see Section 3.1). For the majority of businesses, the reporting unit is the same as the enterprise.
Purchases
The value of all goods and services purchased during the year.
Total employment costs
This includes all gross wages and salaries, overtime payments, bonuses, commissions, payments in kind, benefits in kind, holiday pay, employer's National Insurance contributions, payments into pension funds by employers and redundancy payments less any amounts reimbursed for this purpose from government sources. No deduction is made for Income Tax or employee's National Insurance contributions. Payment to working proprietors, travelling expenses and lodgings allowances are excluded.
Total net capital expenditure
This is calculated by adding the value of new building work, acquisitions less disposals of land and existing buildings, vehicles and plant and machinery.
Total net capital expenditure (acquisitions)
This is calculated by adding the value of new building work, acquisitions of land and existing buildings, vehicles and plant and machinery.
Total net capital expenditure (disposals)
This is calculated by adding the value of disposals of land and existing buildings, vehicles and plant and machinery.
Total stocks and work in progress (increase during year)
This represents the increase during the year for materials, stores and fuel and goods on hand for sale. Amounts for materials that have been partially processed but which are not usually sold without further processing are also included.
Total stocks and work in progress (value at beginning of year)
This represents the value at the beginning of the year for materials, stores and fuel and goods on hand for sale. Amounts for materials that have been partially processed but which are not usually sold without further processing are also included.
Total stocks and work in progress (value at end of year)
This represents the value at the end of the year for materials, stores and fuel and goods on hand for sale. Amounts for materials that have been partially processed but which are not usually sold without further processing are also included.
Turnover
Turnover is defined as the total value of sales. This is calculated by adding together the values of:
sales of goods produced
goods purchased and resold without further processing
work done and industrial services rendered
non-industrial services rendered
Retail turnover by commodity
This only applies to retail sector: division 47. This is a breakdown of the total retail turnover within the retail sector into groupings of like items based upon the European Classification of Individual Consumption by Purpose.
Definitions of other variables and terms used in the production of business statistics can be found in the Eurostat Glossary.
Back to table of contents3. Sampling procedure
3.1 Sampling frame
The Inter-Departmental Business Register
A sampling frame is a complete list of all the members of a population being studied, from which the sample is drawn. The sampling frame for the Annual Business Survey (ABS) is the list of UK businesses on the Inter-Departmental Business Register (IDBR).
Businesses are added to the IDBR if they are:
registered for Value Added Tax (VAT) with Her Majesty’s Revenue and Customs (HMRC)
registered for a Pay As You Earn (PAYE) scheme with HMRC
an incorporated business registered at Companies House
The IDBR covers businesses in all parts of the economy, except some very small businesses; the self-employed and those without employees, both of which are not registered for PAYE, and those with low turnover, which are not registered for VAT; and some non-profit making organisations. There are 2.6 million businesses on the IDBR; covering nearly 99% of UK economic activity. It is used by government departments, including Office for National Statistics (ONS), as the sampling frame for most business surveys.
Administrative data from these sources are supplemented by data from surveys such as the Business Register and Employment Survey (BRES) to keep information on the IDBR up-to-date.
Further information about the IDBR can be found on the IDBR webpages.
In 2015, as described in Improving the Coverage of the Standard Business Survey Population, the coverage of the ONS Standard Business Survey Population was expanded to include a population of solely PAYE-based businesses. This increased the population by approximately 92,000 businesses.
Reporting units
The business unit to which questionnaires are sent is called the reporting unit (Figure 4). The response from the reporting unit can cover the enterprise as a whole, or parts of the enterprise identified by lists of local units. Other than for a minority of larger business or businesses that have a more complex structure, the reporting unit is the same as the enterprise. For this reason, ABS reporting unit counts are presented as enterprise counts.
An enterprise may consist of one or more sub-units (called local units), for example, the head office for a group of shops. An enterprise may therefore have local units at different locations and may carry out more than one type of economic activity.
Figure 4: Relationship between local units, enterprises, enterprise groups, and reporting and administrative units
UK
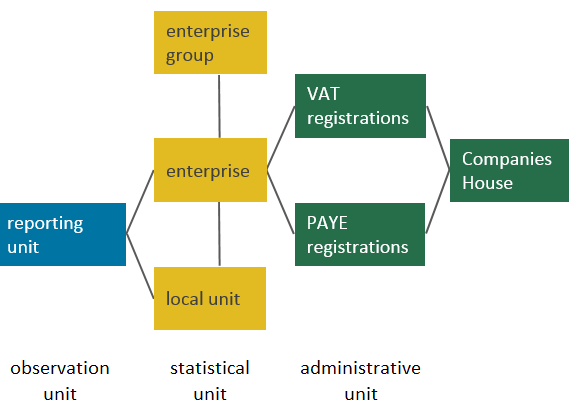
Source: Office for National Statistics
Download this image Figure 4: Relationship between local units, enterprises, enterprise groups, and reporting and administrative units
.png (19.6 kB)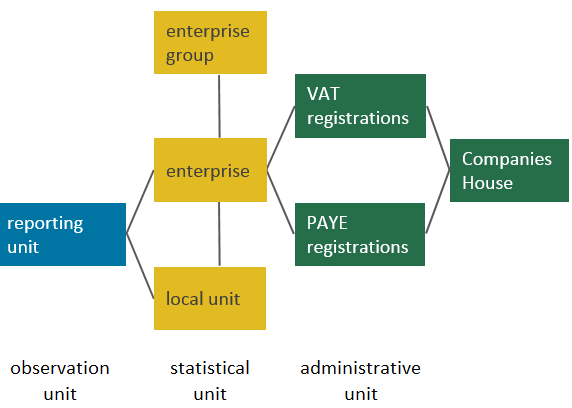{kind=link}
The geography assigned to the enterprise is based on a postcode that is generally the registered office for the business. If this information is used to produce regional estimates it could lead to bias, as the enterprise address given is generally the head office and head offices can be over-represented in big cities such as London and Edinburgh. Therefore, in producing ABS regional estimates, an attempt is made to attribute to regions based on local unit information held on the IDBR. For more information on regional apportionment see Section 5.8.
Standard Industrial Classification (SIC)
Each enterprise is classified according to the Standard Industrial Classification of Economic Activities 2007: SIC 2007 system. The UK is required by European legislation to have a system of classification consistent with the European Union’s industrial classification system. The system underwent a major review in 2007. ABS data have been collected and published on the SIC 2007 system since the reference year 2008. Other revisions to the system occurred in 1958, 1968, 1980, 1992, 1997, and 2003.
UK SIC 2007 is divided into 21 sections, each denoted by a single letter from A to U. The letters of the sections can be uniquely defined by the breakdown to the divisions (denoted by two digits), which are then broken down into groups (three digits), then into classes (four digits) and, in some but not all cases, again into sub-classes (five digits).
For example, in SIC (2007):
section – C: manufacturing (comprising divisions 10 to 33)
division – 13: manufacture of textiles
group – 13.9: manufacture of textiles
class – 13.93: manufacture of carpets and rugs
sub-class – 13.93/1: manufacture of woven or tufted carpets and rugs
The full structure of SIC 2007 consists of 21 sections, 88 divisions, 272 groups, 615 classes and 191 sub-classes.
Each local unit is assigned a single SIC code, which corresponds to the unit’s principal activity. Where more than one type of economic activity is carried out by a local unit or enterprise, its principal activity is the activity in which most of the people are employed, and it does not necessarily account for 50% or more of the total employment of the unit. There are detailed rules for determining SIC for multiple-activity economic units, including situations where measures of value added are not available.
Re-classification of a business can occur due to a relatively small change to the nature of its operation and this can have a significant effect on ABS estimates by industry. In addition, the correction of mis-classification of businesses can lead to bias, particularly where there is systematic movement from one industry to another. This is because, where classification updates are identified through survey returns, it is only units in the survey sample that are updated.
All surveys that do not cover the whole business population, such as the ABS, have the potential for some underestimation of output variables due to the re-classification of units moving out of the ABS survey population, but never into it, however, such underestimation is likely to be small. In the ABS, this effect is corrected for by adjusting the weights of the businesses that remain in the sample.
The industries covered by ABS are:
agriculture (support activities), forestry and fishing – part of section A
production industries – sections B to E
construction industries – section F
distribution industries – section G
other service industries – sections H, I, J, K (insurance and reinsurance, groups 65.1 and 65.2 only), L, M, N, P (excludes public sector), Q (excludes public sector and medical and dental practice activities, group 86.2), R, S
The ABS covers the insurance and reinsurance parts of the financial and insurance sector (groups 65.1 and 65.2 in section K). However, data for this industry have remained experimental and, due to ongoing volatility, it was decided to remove it from the ABS 2012 provisional release onwards.
The main industries excluded by the ABS are:
agriculture – part of section A (crop and animal production, groups 01.1, 01.2, 01.3, 01.4 and 01.5)
financial activities – section K (groups 64, 65.3, 66)
public administration and defence – section O
activities of households as employers; undifferentiated goods and services-producing activities of households for own use – section T
activities of extraterritorial organisations and bodies – section U
3.2 Sample design
Data are collected by Office for National Statistics (ONS) from around 62,000 businesses in Great Britain and by the Northern Ireland Statistics and Research Agency (NISRA) from around another 11,0001 businesses in Northern Ireland.
Sample selection is carried out using a stratified random sample design. Groups of reporting units (cells) are defined by three strata: employment size band; SIC; and geographical region. There are around 4,800 of these cells in the ABS design. Sample selection occurs independently for each cell. When the sample is designed, the size of the sample in each cell is determined by an algorithm, which distributes the sample amongst the cells to give the lowest estimated variance (uncertainty). This design is significantly more efficient (that is, it gives a much more accurate estimate for the same sized sample) than a simple, unstratified random sample.
The strata defining the cells are:
employment size bands: 0 to 9, 10 to 19, 20 to 49, 50 to 99, 100 to 249, and 250 or more
SIC 2007): for England and Wales, four-digit SIC 2007 (class); and for Scotland, two-digit SIC 2007 (division)
region: England and Wales; and Scotland
Where industries have characteristically high employment and low turnover, which can occur for businesses employing largely casual or part-time workers such as market researchers, event catering and cleaning activities, the top two employment size bands are 100 to 999 and 1,000 or more.
The sample design is constructed so that a sample for a cell will generally be selected for two years and the units in that sample will largely not be re-selected for at least two years after that selection. The random sample selection uses the permanent random number (PRN), the unique nine-digit identifier that is randomly assigned to each unit when it is added to the IDBR. The sample from each cell is constructed from the required number of units with consecutive PRNs in that cell.
For the ABS, each sample is generally selected for two years and there is a year-to-year overlap of half the sample. That is, in any year, half of the sample will be newly-selected, and half will have been selected in the previous year as well. This is illustrated in Figure 5, for a sample of four units taken from a cell containing 10 units, where units remain in the sample for two consecutive years (note that these are not real PRNs, as real PRNs have nine digits). This design means that, for half the sample, returns are available from the same businesses in consecutive years and this helps to maintain the quality of editing and validation, imputation and outlier detection (see Section 5).
Figure 5: Example of permanent random number sampling method
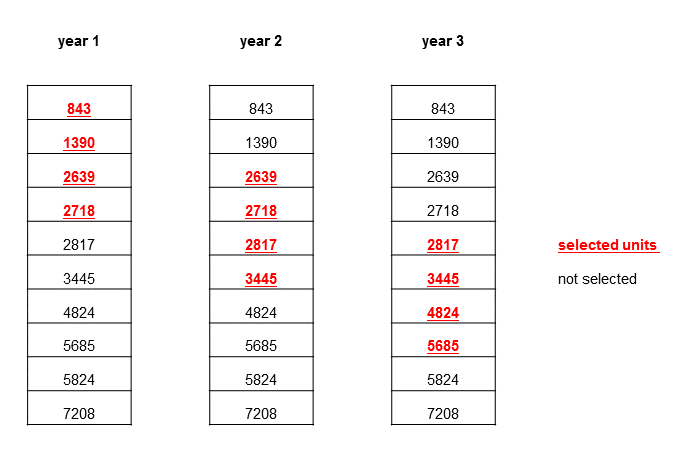
Source: Office for National Statistics
Download this image Figure 5: Example of permanent random number sampling method
.png (22.8 kB)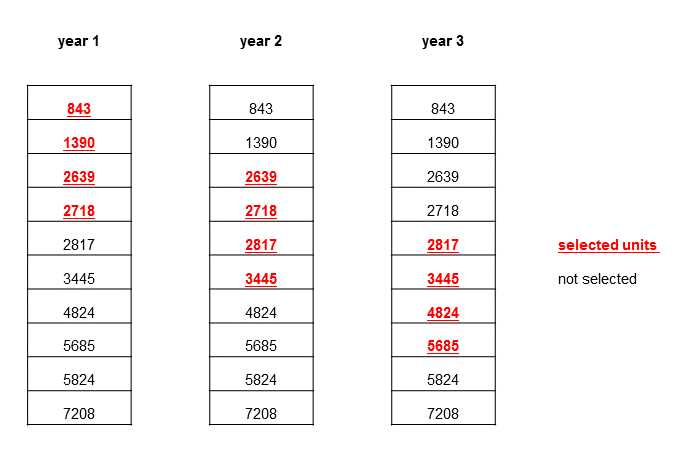{kind=link}
In the first and second year, units 843, 1390, 2639 and 2718 are selected. In the next year, the first two units are dropped, units 2639 and 2718 are retained and the units 2817 and 3445 are brought in to the sample. When the end of the cell is reached, selection rolls around to the beginning.
However, there are a few exceptions to this design. If a selected unit then moves to another cell, for example, by changing SIC classification or employment size band, then it may be selected for a second two-yearly period. Also, if there are fewer units within a cell, the likelihood of consecutive selection will increase. For these reasons, there is never a guarantee that a business will only be selected for two years.
A further exception arises in the cells within the largest and smallest size bands. For the largest size bands, containing businesses with employment of 250 or more, all the enterprises are selected every year. This is because these cells tend to have few enterprises in them and yet, as they are large enterprises, they are dominant contributors to estimated total values. Including all the largest enterprises significantly reduces uncertainty on the estimated total values.
For most businesses with employment of 0 to 9, Osmotherly rules apply. These rules state that when a business with 0 to 9 employment has been selected in a survey, it will only be selected for a single year and it will not be reselected for at least three years following selection. There are a few exceptions to these rules, but in general, they are implemented to reduce the burden on small businesses, which may not have much resource for completing survey questionnaires.
A sample re-optimisation is carried out every five years to improve the efficiency of the sample estimation and reduce sampling variability as part of the regular process to improve estimates.
Notes for: Sampling procedure
- Increasing from 9,000 for ABS 2011 to 11,000 for ABS 2012.
4. Data collection
4.1 Timetable of despatch
The Annual Business Survey (ABS) sample selection for Great Britain for a given year is carried out in November; and finalised in early December of that year. Questionnaires are then printed for a staggered despatch between January and February the following year (see Section 9.2 for Northern Ireland). The total despatch is just over 62,000 questionnaires.
The questionnaires are required to be returned to Office for National Statistics (ONS), in a pre-paid envelope within the two months following the respondents’ business year end.
4.2 Expected receipt
In order to meet the minimum accuracy standards required by its users, the ABS questionnaire response rate target is at least 64% of businesses by the end of August and 74% by the end of December.
4.3 Reminders
If businesses who have received questionnaires have not responded by the deadline, up to three reminder letters can be sent.
The first reminder is despatched at the beginning of June to non-responders. Reminders to businesses in the production sector are despatched before other sectors, as from analysing response data from previous years, they were identified as having the poorest response rates.
The second reminder is despatched towards the end of July. All non-responders with employment of 1,000 or more are sent a Chief Executive Letter (CEL), as opposed to a second reminder, towards the end of July, as their impact on provisional estimates are the greatest.
The third reminder is despatched at the beginning of September. However, if the response rate target for a particular sector has already been achieved, then the third reminder is suppressed. In previous survey years, businesses in the catering, retail and construction sectors most commonly received a third reminder due to their poor response rates.
The CEL is a stronger reminder to inform the chief executive or managing director that their business has not responded, and to remind them of the legal requirement to respond, only one CEL is despatched. The CEL outlines the non-compliance penalties and is sent directly to the chief executive of the business before any enforcement procedures begin.
4.4 Response chasing
Businesses are encouraged to complete ONS surveys to enable the production of quality outputs. This is achieved through effective response chasing and by addressing respondents’ issues in a timely and efficient manner.
The ONS has a strategy in place that targets the economically most important businesses selected.
Responses are followed up in the following order of priority:
businesses with employment of more than 1,000
businesses with an expected turnover of more than £150 million – this ensures that businesses with smaller employment and large turnover are covered
businesses sent long questionnaires – this ensures good coverage for the expansion of the short questionnaires
short questionnaires
Each of the priority groups will start with response chasing the services, production and motor trades sectors first, as from previous experience they tend to take the longest to reach their response targets.
A manual exercise is also undertaken at certain points throughout the data collection cycle to identify industries with a low response. Non-responding businesses in these industries are identified as critical responders and are contacted.
4.5 Enforcement strategy
The ABS carries out enforcement action under the Statistics of Trade Act 1947. Enforcement action is used to maintain response rates and hence the quality of the survey. It is used only as a last resort, after attempts to encourage businesses to complete the survey through telephone calls have been made, and a reminder or CEL has been sent.
If enforcement action is carried out, the business will be issued with a summons to court. The criteria for being summonsed depend on the size of the business:
all non-responders with an employment of at least 500 are issued with a summons when they have failed to respond for just one year
all non-responders with an employment of 250 to 499 will be issued with a summons if they fail to complete the survey for two years running
non-responders with an employment less than 250 will be assessed and will be issued with a summons on a case-by-case basis
If a business receives a summons for a case to be heard against them in court, the business can still choose to respond to the survey and the case will be withdrawn. This option is only allowed once. If the business becomes subject to enforcement a second time, the business will be prosecuted. Businesses can be fined up to a maximum of £2,500.
Back to table of contents5. Converting respondent data into published estimates
5.1 Editing and validation
Questionnaires are sent to businesses by post, along with detailed instructions on how to complete and return them. When responses are received, they are entered into the processing system electronically.
Step 1: questionnaires are electronically scanned into the data store.
Step 2: data are then transferred to the processing system. Initial validation checks are carried out on the returned data. For example, data will fail validation if:
the data are for periods other than the required year
the questionnaire is not the correct type for the business responding
there is an invalid question number on the questionnaire
no questions have been completed
Step 3: after the initial validation further editing is carried out, as detailed in this section.
Automatic totalling
For the main variables total turnover, total employment and total purchases, the sum of the breakdown components on the long questionnaire are checked against the total values entered.
Automatic rounding
Total turnover is requested to the nearest thousand pounds. Where an actual (that is, non-rounded) total turnover is returned, it is common for the responses to other questions to also be returned as actual values and these are then automatically rounded to the nearest thousand pounds.
The automatic correction tests described are only possible if previous period data are available and corrections are within tolerated limits compared with previous data.
Date tests
Some of the date tests carried out are:
start date, end date or length of period covered by the response are outside the acceptable range
more than two days between current start date and the end date of their previous return
previous end date not earlier than current start date
return dates not valid
Selective editing (SELEKT Tool)
SELEKT is a generic selective editing tool. It allows each response to be scored according to a set of agreed criteria, which attempt to give high scores to the errors that will have the largest influence on estimates. Those responses with the highest score are prioritised for editing and validation. This increases the efficiency of the editing process by focusing on the responses with the highest impact and importance. The score can be split into three parts:
- suspicion of an error or mistake
- potential impact on estimate
- importance of the variable
Suspicion of an error or mistake
Variables are assigned a number from zero to one, which quantifies how suspicious we are that the value has been incorrectly entered.
If the returned value passes all validation tests, its suspicion score is zero. If the returned value fails a “fatal edit” test, its suspicion score is set to one.
Fatal edits occur where responses are impossible, for example, if the sum of the components does not equal the total value, or if a non-zero employment cost is returned, but the total employment is zero, and therefore both statements cannot be true. If a returned value fails a fatal edit test, the suspicion score for all the returned variables for that record are set to one. Records that fail fatal edit tests always fail editing, regardless of their impact or importance scores. Note that it is possible for a variable to have a suspicion score of one, without having failed a fatal edit test.
A score between zero and one is awarded where the value is not within the range expected from previous returns. The score is higher the further away from the expected value the returned value is.
Potential impact on estimate
The impact score is a measure of the potential impact on estimates of main variables if the value is in error. Estimates calculated using the returned value are compared with estimates calculated using the value expected from previous returns.
Importance of the variable
For example, issues with main variables such as turnover, purchases and employment costs will be given a higher score than those less important variables such as stocks and capital expenditure.
A variable and question score is then calculated using the following formulas:
variable score equals suspicion multiplied by impact multiplied by importance
question score equals sum of variable score
If the score is lower than the survey threshold, SELEKT allows questionnaires to pass validation. Those questionnaires with inconsistent returned values will fail validation, irrespective of the impact on estimates.
Step 4: when all the data have passed the required tests, and validation failures have been edited, the dataset is considered “clean” and industry estimates for publication can be calculated.
Step 5: the industry estimates are then subject to further quality checks, as described in Section 5.6.
5.2 Imputation
For the ABS to achieve the minimum accuracy required for publication of the provisional estimates in November, at least 64% of the businesses sampled must respond. A higher response rate of 74% is then required by the end of December, increasing the accuracy of the revised estimates published in April or May. Imputation techniques are used to estimate the value of the missing data due to non-response.
Imputation gives better results than deletion, in which all subjects with any missing values are omitted from the analysis. The method uses returned values from similar businesses to estimate values for non-responding sampled businesses.
Imputations are done mainly for large businesses such as those in size band 6 (250 or more employment) and businesses with low employment but high turnover. Imputation is generally for businesses in these groups that do not respond to any part of the survey.
For non-responding small businesses, such as those in size bands 1 (0 to 9 employment), 2 (10 to 19 employment) and 3 (20 to 49 employment), imputation is not carried out and totals are estimated using adjusted weights (see Section 5.4 for a discussion of weighting).
The imputation method used is based upon the principle of ratio imputation where an imputation link is calculated using information from similar business within the same industry and size band. There are various constraints that are applied to calculating these links. The constraints on the responders (in the industry concerned) used to calculate the links are that they must have:
employment of more than 100
returned turnover greater than zero
data available for the previous and current periods
Imputation links for non-responding businesses use the median (middle value) of the ratios. The approach was determined by suppressing real data and running imputation using median ratios, which result in imputed values close to the true value.
The next stage is to check if the business was selected and responded to an ONS short-term inquiry survey covering the required period. If this is the case, the monthly or quarterly figures measured by the short-term survey are used in place of the relevant imputed values. Returned values for a business are likely to be closer to the true value being measured, however, the short-term surveys do not collect information for all variables covered by the ABS so this approach is only possible for a limited set of variables.
Case 1: businesses that have responded in the previous period
For example, if business X has not returned a value for total turnover in the current period, but did in the previous period, businesses in the same sector that have returned a value for total turnover in the current period are considered.
Of these, those who have returned a value for total turnover for both the current and the previous periods are identified. The ratio of the current value of total turnover to the previous value for total turnover is then calculated.
For each responding business to both periods:
The median ratio value, referred to as the imputation link, is then calculated and applied to the returned value for the non-responding business in the previous period.
Table 4 shows how a turnover value for business X could be imputed.
Table 4: Example imputation of turnover value for business that has responded in previous period
| Business | Turnover in period (T-1) / £1,000s | Turnover in period T / £1,000s | Ratio = turnover(T) / turnover(T-1) |
|---|---|---|---|
| A | 50 | 60 | 1.200 |
| B | 45 | 50 | 1.111 |
| C | 52 | 49 | 0.942 |
| X | 48 | ? | |
| E | 75 | 82 | 1.093 |
| F | 64 | 64 | 1.000 |
| Source: Office for National Statistics | |||
Download this table Table 4: Example imputation of turnover value for business that has responded in previous period
.xls (28.2 kB)Median of ratios: imputation link equals 1.093.
Imputed value for X in period T: turnover for X in period T-1 multiplied by median of ratios equals 48 * 1.093 = 52.5.
Case 2: businesses that are first-time responders
In the example in Table 5, business X is a first-time responder and so does not have any returned values for the previous period. In these cases, the turnover of businesses held on the IDBR is used in the calculation of the imputed value for X.
Table 5: Example imputation of turnover value for business that has not responded in previous period
| Business | Turnover in period (T-1) / £1,000s | Turnover in period T / £1,000s | IDBR turnover / £1,000s | Ratio (turnover(T) / IDBR turnover) | ||
|---|---|---|---|---|---|---|
| A | 36 | 42 | 44 | 0.97 | ||
| B | 19 | 16 | 23 | 0.70 | ||
| C | 6 | 8 | 6 | 1.35 | ||
| X | - | ? | 40 | |||
| E | 98 | 97 | 65 | 1.49 | ||
| F | 85 | 102 | 90 | 1.13 | ||
| Source: Office for National Statistics | ||||||
Download this table Table 5: Example imputation of turnover value for business that has not responded in previous period
.xls (36.4 kB)Median of ratios equals 1.13.
Imputed turnover for X in period T: IDBR turnover of X multiplied by median of ratios equals 40 * 1.13 = 45.
When calculating median ratios as described previously, the calculation routine will attempt to identify respondents at a four-digit SIC level. Should for some reason there be no median at this level (for example, due to insufficient number of businesses), the routine will try to use a median calculated at three-digit SIC level. If this fails to find a median, the routine will try at the two-digit SIC level.
5.3 Expansion
As described in Section 2, the ABS has two questionnaire types: long and short. The short questionnaires are mainly sent to small businesses and only ask for totals such as total turnover or total purchases. The long questionnaires are mainly sent to large businesses and a sample of smaller ones and ask for components of those totals, such as any other income and sales of goods of own production, in addition to overall totals. This method is used to reduce the response burden on smaller businesses.
The values of the components therefore need to be estimated for the businesses that received short questionnaires. This is done by calculating component proportions for those businesses returning long questionnaires and using these proportions to estimate the size of the components for the other businesses. This process is called expansion. Ideally, proportions are calculated from (long questionnaire) businesses in the same employment size band and same four-digit SIC industry (“cell”) as those (short questionnaire) businesses that are being estimated for. However, this is not always possible, so the rules for expansion are:
if there are at least five returned long questionnaires in the cell, then expansion can go ahead using only businesses in that cell
if there are fewer than five returned long questionnaires, then employment size bands are combined until at least five returned long questionnaires are found; sometimes all size bands have to be combined and in this case, if there are at least three returned long questionnaires within the cell, these are used (the combining of size bands within each four-digit SIC industry occurs in accordance with Table 6)
if there is still an insufficient number of long questionnaires, responses for the whole two-digit SIC are used
Table 6: Combining size bands within four-digit Standard Industrial Classification 2007 industries
| Employment | Size band on 1st attempt | Grouped size bands on 2nd attempt | Grouped size bands on 3rd attempt | Grouped size bands on 4th attempt | Grouped size bands on 5th attempt | Grouped size bands on 6th attempt | |
|---|---|---|---|---|---|---|---|
| 0 to 9 | 1 | 1 and 2 | 1 to 3 | 1 to 4 | 1 to 5 | 1 to 6 | |
| 10 to 19 | 2 | 1 to 3 | 1 to 4 | 1 to 5 | 1 to 6 | ||
| 20 to 49 | 3 | 2 to 4 | 1 to 5 | 1 to 6 | |||
| 50 to 99 | 4 | 3 to 5 | 2 to 6 | 1 to 6 | |||
| 100 to 249 | 5 | 4 to 6 | 3 to 6 | 2 to 6 | 1 to 6 | ||
| 250 and over | 6 | Expansion is not applied to size band 6, as they are all long questionnaires | |||||
| Source: Office for National Statistics | |||||||
Download this table Table 6: Combining size bands within four-digit Standard Industrial Classification 2007 industries
.xls (36.9 kB)The expansion is then carried out using one of the two methods described in this section. The method used depends on the component being estimated. An example calculation is shown for each method.
Method 1: expansion using ratios
This expansion is used to break down totals returned on short questionnaires, for example, total turnover, into individual components, for example, the value of sales of goods of own production. The method uses the ratio of components to totals from the long questionnaire as follows:
for each long questionnaire component, the sum of all the returned values is calculated; this is divided by the sum of the long questionnaire returned totals and multiplied by 100 to get a percentage contribution for each component to the total
this percentage is then used on the short questionnaire returned total to get an estimate of the short questionnaire component
Tables 7 and 8 provide an example where the total turnover from the long questionnaire is used to get a value of sales of goods of own production using expansion. Consider the data obtained from the short questionnaire for total turnover for five businesses, and that from 12 other businesses that returned the long questionnaire.
Table 7: Example short questionnaire responses for use in expansion using ratios
| Business | Total turnover (£) |
|---|---|
| A | 35,527 |
| B | 34,280 |
| C | 42,080 |
| D | 25,178 |
| E | 21,730 |
| Source: Office for National Statistics | |
Download this table Table 7: Example short questionnaire responses for use in expansion using ratios
.xls (35.3 kB)
Table 8: Example long questionnaire responses for use in expansion using ratios
| Business | Sales of goods of own production (£) | Total turnover (£) |
|---|---|---|
| F | 42,000 | 42,000 |
| G | 25,000 | 25,000 |
| H | 24,039 | 24,039 |
| I | 12,771 | 29,325 |
| J | 20,840 | 20,886 |
| K | 31,635 | 31,635 |
| L | 31,680 | 32,568 |
| M | 15,470 | 15,470 |
| N | 0.00 | 5,748 |
| O | 21,240 | 21,240 |
| P | 44,651 | 44,651 |
| Q | 8,946 | 9,160 |
| Total | 278,272 | 301,722 |
| Source: Office for National Statistics | ||
Download this table Table 8: Example long questionnaire responses for use in expansion using ratios
.xls (36.4 kB)Ratio equals sum of components divided by sum of totals (278,272 divided by 301,722 equals 0.9223).
Percentage: 0.9223 multiplied by 100 equals 92.23%.
Using expansion, the value of sales of goods of own production for the short questionnaire can be calculated (Table 9).
Table 9: Example expanded short questionnaire responses using ratios
| Business | Turnover (£) | Estimated value of sales of goods of own production (= turnover * 92.23 %) (£) |
|---|---|---|
| A | 35,527 | 31,616 |
| B | 34,280 | 32,766 |
| C | 34,280 | 38,810 |
| D | 25,178 | 23,221 |
| E | 21,730 | 20,041 |
| Source: Office for National Statistics | ||
Download this table Table 9: Example expanded short questionnaire responses using ratios
.xls (35.8 kB)Method 2: expansion using per head of employment values
This expansion is used for standalone questions with no totals, for example, insurance claims received, that are not asked on the short questionnaire. The procedure is as follows:
for each returned value from the long questionnaire, the value per head of employment is calculated, by dividing the value of the variable by the businesses’ employment
the mean value per head of employment is then found by taking the sum of values per head and dividing it by the number of businesses
the mean value per head of employment is multiplied by the number of people in employment in the business to calculate the value for insurance claims received for the short questionnaire
For example, using the total turnover on the long questionnaire, the short questionnaire value for the variable any other income is found. The choice of what size bands are included in the expansion calculation follows the rules set out earlier in Table 6. In this example, the short questionnaires were sent to businesses in size bands 1 or 2. In order to find at least five returned long questionnaires in the same industry, businesses in size bands 2, 3 and 4 were included in the calculation also (Table 10).
Table 10: Example long questionnaire responses for use in expansion using per head of employment values
| Business | Size band | Employment | Any other income (£) | Any other income per head of employment (£) |
|---|---|---|---|---|
| A | 2 | 13 | 0 | 0 |
| B | 3 | 30 | 0 | 0 |
| C | 4 | 69 | 0 | 0 |
| D | 4 | 58 | 0 | 0 |
| E | 4 | 82 | 0 | 0 |
| F | 4 | 50 | 0 | 0 |
| G | 4 | 55 | 35 | 0.636 |
| Total | 0.636 | |||
| Source: Office for National Statistics | ||||
Download this table Table 10: Example long questionnaire responses for use in expansion using per head of employment values
.xls (36.4 kB)Mean any other income per head of employment: 0.636 divided by 7 equals £0.091 per head of employment.
Using the mean per head of employment value, the value for any other income for the short questionnaire is calculated (Table 11).
Table 11: Example expanded short questionnaire responses using per head of employment values
| Size band | Employment | Estimated any other income (£) (= employment * 0.091) |
|---|---|---|
| 1 | 2 | 0.18 |
| 1 | 4 | 0.36 |
| 1 | 7 | 0.64 |
| 1 | 8 | 0.73 |
| 1 | 3 | 0.27 |
| 1 | 2 | 0.18 |
| 2 | 19 | 1.73 |
| 2 | 15 | 1.37 |
| Source: Office for National Statistics | ||
Download this table Table 11: Example expanded short questionnaire responses using per head of employment values
.xls (35.8 kB)5.4 Estimation of totals
It is not possible to collect data on every UK business every year, because:
the burden on businesses would be too great
the cost of running such a census would be prohibitive
a well-designed sampled survey can produce better estimates than a census with a poor response rate
Therefore, the ABS collects information from a sample of the UK business population each year. The sample design is described in Section 3.2. This section describes how returns from the sample are used to estimate totals for the whole population.
Weighting
In order to calculate the estimates for an entire population from data collected from a sample, the ABS uses standard statistical weighting methods. Essentially the results received from the sample are multiplied by two weights: the a-weight and the g-weight.
The a-weight, also known as the design weight, accounts for the sample design so that a business’ probability of selection is properly reflected. So, for example, a business with a small probability of being selected for the survey will have a large design weight.
The g-weight, or calibration factor, makes a correction for any potential bias in the selected sample. For example, in a random selection of five businesses out of a population of 10, it is possible that the five businesses selected have, by chance, higher values for the variables of interest than the non-sampled businesses. If no correction is made, the population total would be over-estimated. Auxiliary information, such as information not collected by the survey, which acts as a proxy for the variable of interest, is used to correct for this effect. The ratio of the actual population total for the auxiliary variable to the population total estimated from the sample’s auxiliary variables is calculated and this is called the g-weight. For the ABS, the auxiliary variables are the IDBR employment and turnover, with the choice dependent on the variable being estimated.
The weighted value is calculated as:
weighted value = returned value of the variable * a-weight * g-weight
Estimates of population totals are then found by simply summing the weighted values over the whole sample.
Calculating the a-weights and g-weights
A-weights
An a-weight is calculated for each cell in the sample. A cell, or stratum, is a group of businesses defined by their size and industry (see Section 3.2). In its simplest form, the a-weight, a, for each cell is calculated as:
Where N is the total number of businesses in the cell (the population) and n is the number of businesses in the sample. For example, to estimate the weight of a pile of 50 bricks, 10 bricks could be weighed. N, the total number of bricks is 50; n, the sample size, is 10; and a is therefore 50 divided by 10 equals 5.
However, for the ABS, an adjustment is made. It is possible for businesses to stop trading between the time the sample is selected (November) and the time the questionnaires are despatched (January or February). This is called a business “death”. In some cells, there will also be (unknown) “births” in the population – businesses that start trading but are not included in the sampling frame. To avoid bias, the a-weights are adjusted in cells where births have occurred, using assumptions pertaining to the relationship between the number of births and the number of deaths.
The adjusted a-weight is calculated as:
Where for each cell:
N is the total number of businesses
n is the number of businesses in the sample
h is the birth or death constant: h equals 1 for a sampled cell (assuming one birth for every death), and h equals 0 for a fully enumerated cell (assuming no births)
d is the number of deaths
So, for example, for a sampled cell, if:
N equals 1,247
n equals 19
h equals 1
d equals 1
Then the a-weight, a equals 69.3.
G-weights
G-weights are calculated for groups of cells with the same industry, but across several size bands. Generally, size bands 1 (0 to 9 employment), 2 (10 to 19 employment) and 3 (20 to 29 employment) are grouped for the calculation of g-weights. These groups are called g-weight bands.
In its simplest form, the g-weight is the ratio between the total of the auxiliary variable estimated from the sample and the actual population total for the auxiliary variable. The g-weight will therefore be greater than one when the total auxiliary estimated from the sample is less than the total auxiliary in the population, and less than one when the total auxiliary estimated from the sample is more than the total auxiliary in the population. In a well-designed sample, all the g-weights should be close to one. The g-weight therefore helps correct for any imbalances in the selected sample that arise through random chance or non-response.
The g-weight is calculated as follows:
g = Tpop / (Tsamp * (N/n))
Where:
Tpop is the sum of IDBR turnover (or employment) over all businesses in the population
Tsamp is the sum of IDBR turnover (or employment) over all businesses in the sample
N is the number of businesses in the population
n is the number of businesses in the sample
Tsamp*(N/n) is the total for the auxiliary estimated from the sample.
However, for the ABS, the g-weights are also subject to a correction for business deaths, and the adjusted formula is as follows:
Where:
Tpop is the sum of IDBR turnover (or employment) over all businesses in the population
Tsamp is the sum of IDBR turnover (or employment) over all businesses in the sample
Td is the sum of IDBR turnover (or employment) over all businesses that have died
N is the number of businesses in the population
n is the number of businesses in the sample
h is the birth or death constant: h equals 1 for a sampled cell (assuming one birth for every death) and h equals 0 for a fully enumerated cell (assuming no births)
d is the number of deaths
So, for example, if:
Tpop equals 217,539
Tsamp equals 2008
Td equals 134
N equals 1,247
n equals 19
h equals 0
d equals 1
then:
The g-weight, g equals 1.68.
Where more than one size band is included in the calculation of the g-weight, the equation becomes:
Where: i equals 1 for businesses in size band 1, i equals 2 for businesses in size band 2, and i equals M for businesses in size band M.
Businesses that are in the largest employment size band, generally those with employment of 250 or more, are given a g-weight of one. For some types of business (for example, employment agencies) the largest employment size band is 1,000 or more.
5.5 Identifying and processing outliers
Occasionally a business returns a different pattern of results from the other businesses within its cell. If a business’ returned turnover is very different from its IDBR turnover, or if a particular variable is proportionally much higher or lower than others in the same cell, then the business’ return is atypical. Hence, this business is an outlier.
It is the nature of business survey populations that there are often a small number of unusual values, or outliers, within sampled strata. Outliers are a common problem in business surveys which, if left untreated, can have a large impact on the variability of survey estimates.
The outliering process is a trade-off between introducing a small bias and reducing the variability of estimates and starts with an assumption that the data returned are correct, that is, they have not been mis-entered, although figures are validated as much as possible before any decision to outlier them is taken. For the ABS, an outlier is defined as a returned value that has a very large influence on an estimate. This can be an unusually large value or an unexpected value with a large weight.
Identification of outliers
There are two separate processes for identifying outliers in the ABS – one automatic, and the other manual.
Automatic outliers
Automatic outliers are identified when automatically processing results.
Outliers are identified if the ratio of returned turnover to IDBR turnover is high. This is calculated as follows:
returned turnover/ (1 + IDBR turnover) > 50
Division by zero is avoided by using (1 + IDBR turnover) in the denominator. If the returned turnover is more than 50 times the IDBR turnover, an outlier is flagged.
Manual outliers
Manual outliers are identified during results investigations by expert judgement from staff.
The considerations taken into account before identifying a manual outlier are:
the level of grossed figures for all other contributors, in the same size band, in comparison with our potential outlier
the ratio of the returned turnover to the registered turnover for the business; the effect it will have on the aggregates for all variables in the industry and the series of year-on-year data
ensuring an unacceptable level of bias is not introduced into the series by identifying too many outliers within the same size band and industry
the number of responses in the size band – if the number is low, size bands can be joined together for calculating the g-weights and the identification of too many outliers could increase this effect
Treatment of outliers
When the outliers have been identified, the businesses are removed from their size band and treated. The method the ABS uses to treat outliers is known as the post-stratification method. In this method, the weights of the outliers are treated so that they do not have a large effect on the estimates. Post-stratification is a special case of weight modification where the weights of the outliers are reduced to one.
The weights for the original size band are recalculated once the distorting business has been removed.
This approach reduces the weights associated with sampled outliers and increases the weights associated with sampled non-outliers. In most cases, the weight of the outlier that is treated is the final weight, which is the product of a-weight and g-weight. The method assumes that the sampled outliers are the only outliers in the population.
Using a simple example, consider a population without stratification and where only design weights are used in the estimation:
Let:
N equals population size
n equals sample size
n1 equals number of non-outliers in sample
n2 equals number of outliers in sample
The original weight is calculated as follows:
The post-stratification method is to:
decrease sampled outlier’s weight from
increase sampled non-outliers’ weights from
This method:
places outliers in a separate “1-in-1” sampled cell, so that each outlier represents itself only (as it is non-representative)
having removed those outliers from their original cells, allows the weights of the remaining non-outliers in the cell to be recalculated
In this example a simple random sample of 13 businesses is taken from a population of 100 for the variable employment:
Table 12: Example businesses by employment to demonstrate outlier treatment
| Business | Employment |
|---|---|
| A | 1 |
| B | 2 |
| C | 3 |
| D | 4 |
| E | 5 |
| F | 5 |
| G | 6 |
| H | 7 |
| I | 8 |
| J | 10 |
| K | 15 |
| L | 80 |
| M | 100 |
| Total | 246 |
| Source: Office for National Statistics | |
Download this table Table 12: Example businesses by employment to demonstrate outlier treatment
.xls (35.8 kB)Businesses L and M are identified as outliers, as they have returned significantly higher values than the other businesses in the cell. These are the only outliers in this population.
Case 1: outliers are not treated
Original a-weight is calculated as follows:
Estimate of the employment is calculated as:
Case 2: using the post-stratification method to treat the outliers
Non-outliers’ adjusted a-weight is calculated as:
Outliers’ weight = 1
New estimate of employment:
5.6 Post-results processing validation
Post-results processing validation refers to the stage where checks are done on the final industry results before publishing.
These checks are carried out by different teams in charge of the specific industries; however, for all the teams the checks are done in a similar way. Figure 6 shows how the checks are carried out.
Figure 6: Post-results validation checks
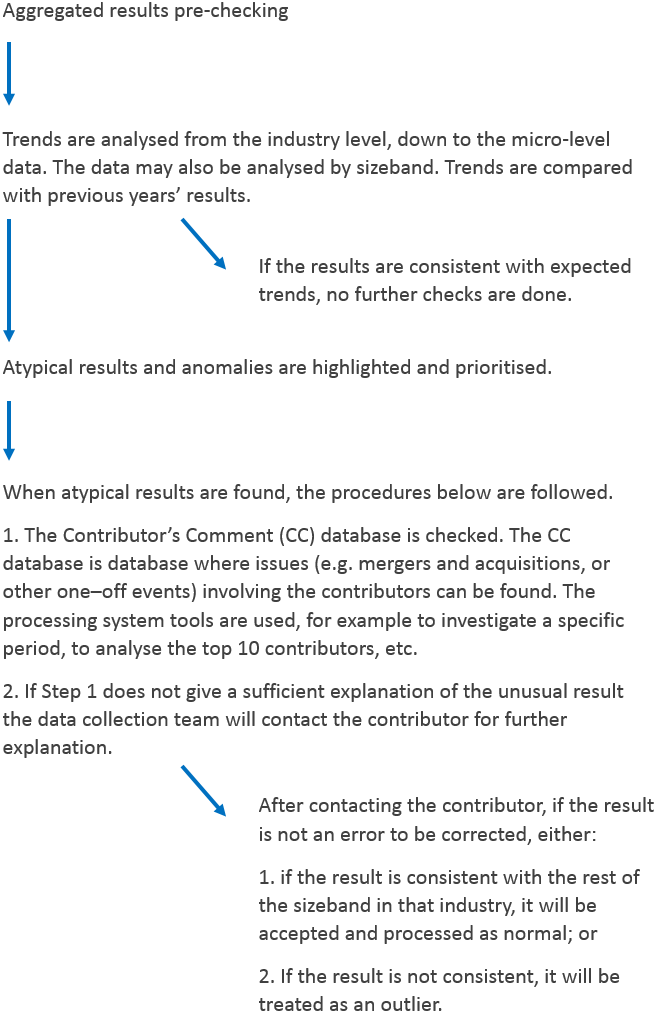
Source: Office for National Statistics
Download this image Figure 6: Post-results validation checks
.png (81.4 kB){kind=link}
5.7 Production of standard errors
Standard errors are a measure of uncertainty. The standard error is one of the main measures of survey quality; it indicates the extent to which the estimates would be expected to vary over repeated random sampling.
The ABS uses stratified sampling and both separate and combined ratio estimation to estimate totals. A standard approach is then used to estimate the variance, from which standard errors can be calculated.
The size of the standard error is a function of the cell sampling fractions, population and sample sizes, and of how much variation there is in the values returned for different businesses in the same cell. A well-designed stratified sample will seek to minimise the variation within a cell. For the ABS, this means that the strata which define the cells are industry and employment size, where businesses in the same industry and similar employment are expected to have similar turnovers and employment costs.
Variance estimation of the ratio estimators in stratified sampling
The formula given in this section is used for calculating ratios in stratified sampling for both the combined ratio data estimate and the separate ratio data estimate. The formula is for the total variance, but it can be adapted to calculate variance for various domains (such as further breakdowns by, for example, industry or geography).
The variance of the estimator of the total in some domains is calculated as:
The standard error of estimates from stratified sampling is found by calculating the positive square root of the estimated variance. The standard error of the estimate is calculated as:
5.8 Regional apportionment
Background
The ABS collects data at reporting unit level (each business) using the Inter-Departmental Business Register (IDBR) as the sampling frame. Generally, reporting units are the same as the enterprise (which is the legal entity of the business) but larger enterprises can be split into a number of reporting units based on divisional structure, geographical considerations, type of activity, or other agreed reporting structures. Reporting units return total values that represent one or many local units of that business. Local unit information is not requested in addition to reporting unit information due to the extra burden this would place on businesses.
To produce ABS regional data, the reporting unit data must be apportioned amongst the local units of that business. Regional data are apportioned based on local unit industry classification, employment size and regional location.
All ABS national results for the UK are produced using reporting unit data and the UK national total for each variable at the "all industry" level is the figure that the regional estimates for that variable will add up to.
Apportioning to local units
Regional estimates are based on local unit information. Each reporting unit has at least one local unit attached to it (or if there is no local unit then the reporting unit is also classed as a local unit for regional purposes).
At the time of selecting the ABS sample, information from the IDBR such as employment, industry and region for every reporting unit is saved and stored for results purposes. In addition, a local unit register is saved, which links each reporting unit to the related local units, as well as giving full geographic, industry and size (employment number) detail about all local units.
The regional ABS methodology uses information held on the IDBR for local unit employment to compile detailed estimates below the national level. Since no local unit information is collected by the ABS, the reporting unit data are apportioned amongst the constituent local units in line with a regression model. The covariates used in this model are industry (mainly three-digit SIC 2007), geography (English regions and UK countries), and size bands (eight employment size bands: 1 to 2, 3 to 4, 5 to 9, 10 to 19, 20 to 49, 50 to 99, 100 to 249 and 250 or more). The model parameter estimates are obtained by fitting the model that best predicts the data gathered from reporting units with very few local units.
The ABS reports primarily at Nomenclature of Units for Territorial Statistics (NUTS) 1 level and provides analysis at lower levels by request. An example of how the NUTS classification system works can be found in Annex D.
In simple terms, the fitting of a regression model is the process of using the relationship between known inputs (called covariates) and unknown (or dependent) variables. Regression coefficients are estimated to minimise the error in the predicted value of the dependent variables. Two methods are used to estimate the regression coefficients – Generalised Linear Model (GLM) and Categorical Data Modelling (CATMOD).
The input to GLM and CATMOD is the reporting unit data of units with fewer than three local units and less than 100 employment (as these are believed to behave most like local units). The initial intention was to use only GLM to produce a single set of regression coefficients, but the large number of zero value data items distorted the shape of the overall distribution.
The zeros were removed from the analyses of variance and modelled separately using a LOGIT transformation (CATMOD), which performs much better on this type of data. Therefore, there are two apportionment weights, which are combined to apportion the reporting unit data to local units. Each variable is apportioned independently with its own set of weights. At the end of the apportionment process the sum of the data allocated to the local units is constrained to be the same as the returned data of the original reporting unit.
Once the data have been apportioned to local units for returned reporting units, then totals are estimated for English regions and UK countries. At the "all industry, all region" level, the regional data are constrained to equal the national total for each variable using a scaling factor, which is then applied to every local unit.
Estimating totals for detailed levels of geography
There is a threshold below which the number of returns in any given year makes the data too volatile to use for regional apportionment. This threshold is known as the minimum domain level. Below this level synthetic estimation replaces actual data. The minimum domain level is generally the two-digit SIC 2007 and NUTS3 level, but other levels exist for certain industries.
Data are apportioned to local units and estimated to population level as detailed previously, then the levels of data lower than the minimum domain are aggregated to the minimum domain level and then re-allocated below this level based on a per head of local unit employment. This reduces the impact that differing samples from year to year can have on the small area estimates.
Industry totals
Although the sum of the regional data for each variable exactly matches the overall national totals, they do not match at any industry level below "all industry" totals because the local unit classification (rather than the reporting unit classification) is used for regional results. Therefore, the national estimate of gross value added (GVA) for retail (SIC 2007 industry 47) for instance will be different from the regional estimate of GVA for retail across all regions.
5.9 Keeping respondents’ data confidential
Confidentiality protection requirement by law and Government Statistical Service (GSS) policy
The need to keep records of individuals, businesses or events used to produce official statistics confidential is enshrined in law. However, this does not prevent the release of anonymised or aggregated data.
The Code of Practice for Statistics and the National Statistician’s guidance: Confidentiality of Official Statistics provide the Government Statistical Service (GSS) policy framework for official statistics in this regard. The Code of Practice guarantees confidentiality to those who provide private information for the production of official statistics.
Furthermore, ONS surveys are conducted on behalf of the UK Statistics Authority and all outputs are subject to Section 39 of the Statistics and Registration Service Act 2007.
Business surveys operating within the UK are governed under the Statistics of Trade Act 1947. This states that tables should not be published that would disclose any information relating to an individual business, unless there is expressed consent in writing from that business.
ONS is now fully compliant with the GDPR regulation.
ONS Confidentiality pledge
The confidentiality pledge is an assurance of confidentiality given to survey respondents.
“All the information you provide is kept strictly confidential. It is illegal for us to reveal your data or identify your business to unauthorised persons.”
Statistical disclosure control and ONS
The Statistical Disclosure Control Policy sets out the standards for safeguarding the information provided in confidence to ONS. Disclosure control refers to the methods that reduce the risk that confidential information is published in any official statistics. These methods are applied if ethical, practical or legal considerations require the data to be protected. Disclosure control involves modifying data so that the risk of identifying individuals is reduced, but at the same time attempts to find a balance between improving confidentially protection and maintaining an acceptable level of quality in the published data.
Statistical disclosure control is applied to the ABS data before publication.
Identifying disclosive data for the ABS
The design of the ABS means that totals can be estimated for each industry and employment size band. However, these totals are usually aggregated for publication purposes, for example, to all businesses in an industry, or to higher-level industry groups. Combining totals like this improves the statistical quality of the estimates and reduces the risk of disclosure. It is at the aggregated level that disclosure control is carried out. The first step is to identify whether data could be disclosive, that is, whether there is a risk that information about an individual business could be identified.
In the following discussion, a “cell” refers to an element of a published table, containing the aggregated data (as described previously), not to the sampling cells described in Section 3.2. For tables of total values published by the ABS, there are two criteria that must be met in order for the published value to be deemed non-disclosive.
These are:
minimum threshold rule: this rule states that there must be at least n reporting units (businesses) in a cell
p% rule: this rule states that the total contribution of the m largest contributors to the cell aggregated total must be less than p% of the total in that cell
The values of n, m and p should remain confidential. Knowing these values could allow information on individual businesses to be calculated.
In this example, there are 10 businesses in a cell, of which four have returned their total turnover estimates and n equals 3, m equals 1, and p equals 95%.
Table 13: Example of disclosure control
| Business | A | B | C | D | E | F | G | H | I | J |
| Total turnover (£1,000) | - | 20 | 30 | - | 5 | - | 1,500 | - | - | - |
| Source: Office for National Statistics | ||||||||||
Download this table Table 13: Example of disclosure control
.xls (35.3 kB)The two criteria are applied to the data as follows.
Threshold rule
There are four businesses that have reported values. The minimum threshold, n, is 3, so the cell is not disclosive under this rule.
p% rule
Total returned turnover of the cell = £(20+30+5+1,500) thousand equals £1,555 thousand, m is one, and the largest contributor is business G, with a total turnover of £1,500 thousand.
So, the percentage contribution of business G to the total turnover in the cell is calculated as follows:
(1,500 / 1,555) x 100% = 96.5%
In this case, 96.5 is greater than 95%, so under this rule, the cell is disclosive.
As the cell has not met both criteria, it is identified as a disclosive cell and disclosure control methods must be applied before the data can be published.
Disclosure control methods
There are several standard techniques for controlling disclosure used on ABS results. These are described in this section.
Cell suppression
Cell suppression is the standard method used to protect tables with disclosive cells. The disclosive cells are suppressed, that is, they are not published. This is known as primary suppression. Other, non-disclosive cells must sometimes also be suppressed, to prevent the values of the primary suppressed cells from being calculated by subtraction of all the other cells from the total. These are known as secondary suppressions. This is the method used by the ABS to suppress disclosive values.
Merging of cells
Cells may also be combined to prevent publication of disclosive data, for example, where there are very few industries in a specific sector, a higher industry classification will be used instead.
Rounding
Monetary estimates in our standard releases are rounded to the nearest £ million or £ billion, with employment data rounded to the nearest 1,000. Percentages or rates displayed in ABS releases must be derived from the unrounded values and then the percentages rounded to one decimal place.
Further information
For more information, see the ONS disclosure control policy for tables.
5.10 Final quality assurance
This section describes the quality assurance carried out on the ABS results when they are aggregated to industry and geographical totals.
The national results are quality assured before the regional results. When the regional results are produced, they are checked against national results. Any further issues that arise due to the process of producing the regional estimates are fed back to the national results, which are adjusted as necessary before publication.
The quality assurance process is as follows:
data aggregated to two-, three- and four-digit SIC level are compared with results from the last three years
large or unusual movements are investigated down to individual business level and followed up with respondents where appropriate
totals are checked for consistency, including one-digit totals, overall totals and, for the regional results, the sum of the regional totals is checked for consistency with national totals
sense checking occurs in collaboration with ONS economists, as the commentary for the statistical bulletin is put together, so that the results are understood in the wider economic context
the results are finally signed off by the ABS output manager and the relevant Divisional Director
6. Revisions policy
Office for National Statistics (ONS) ensures that published estimates are as accurate as possible. However, if significant changes are made to source data after publication, then estimates will be revised. We have a clear policy on how revisions are handled across the organisation and the specific procedure for the Annual Business Survey (ABS) is outlined in Sections 6.1 and 6.2.
6.1 Planned revisions
Planned revisions usually arise from either the receipt of additional data from late responding businesses or the correction of errors to existing data by businesses responding to the ABS.
These revisions to published ABS data can be expected at the following times in the normal course of operation of the ABS:
national figures for the current reference year will usually be revised between the provisional and revised data releases
national figures for the previous reference year will be revised at the current survey year's revised data release
regional figures for the previous reference year will be revised alongside the provision of the current survey year’s data
As an example, provisional national data for 2016 were first published in November 2017 and were then revised in the May 2018 release. At the same time (May 2018), national data for 2015 were also revised.
Revised regional data for 2016 were first published in May 2018. At the same time (May 2018), regional data for 2015 were also revised in final.
A table showing the size of revisions is published alongside the statistical bulletins and revised estimates of significant magnitude will be highlighted and explained in the statistical release.
All other revisions will be regarded as unplanned and will be dealt with by non-standard releases (see Section 6.2). All planned revisions will be released in compliance with the same principles as other new information.
6.2 Unplanned revisions
In addition to planned revisions to the current and previous survey years, additional unplanned revisions may be published if they are considered to be large enough and of sufficient interest to users such that a delay until the next standard release is not justifiable, or if they effect data in more than just the current and previous survey years. The timing with which these revisions are released will consider:
the need to make the information available to users as soon as is practicable
the need to avoid two or more revisions (to the same data items) in quick succession, where this might cause confusion to users
All unplanned revisions will be released in compliance with the same principles as other new information.
Back to table of contents7. Employment estimates
7.1 Background
This section describes the employment data published in the Annual Business Survey (ABS) releases. The ABS does not collect employment level information so instead this key information is taken from another source. In the past, employment data were collected via the Annual Business Inquiry – Part 1 (ABI/1), however, in 2009, ABI/1 was replaced with the Business Register and Employment Survey (BRES). The ABS and BRES are both optimal for their respective purposes, however, caution should be taken when combining the financial data from the ABS and employment information from BRES to calculate estimates due to differences in methodology (see Section 7.2).
It is not currently possible to automatically process the BRES data for inclusion with ABS analysis, however, it is possible to include employment variables in the ABS releases through manual deliveries of data from the BRES team.
7.2 Comparison of ABS and BRES
As mentioned previously, caution should be taken when interpreting productivity measures created using employment information included within ABS publications as it is collected by a separate survey, BRES.
BRES has wider industrial coverage than the ABS, however, even when BRES results are refined to have the same industrial coverage as ABS, differences remain. ABS and BRES have different:
sample selection periods
sample designs
questionnaire reference periods
Sample selection periods
The sample for the BRES is selected from the Inter-Departmental Business Register (IDBR) in August (changed from October in 2005 to bring ABI/1 in line with the Business Register Survey (BRS)) compared with November for the ABS. This change means that the BRES and the ABS no longer share a sampling frame created at the same point in time and these frames differ due to births, deaths and the general movement of businesses between industries.
For further information on the IDBR sampling frame, see Section 3. As an example, a variable such as turnover per head is calculated using an estimate for the turnover based upon a sample of businesses in existence in October, divided by an estimate for the number in employment for businesses in existence at a point in time two months earlier.
Sample designs
The ABS sample is stratified at four-digit Standard Industrial Classification 2007: SIC 2007 class level while the BRES sample design is stratified at the higher two-digit division level.
Questionnaire reference periods
The ABS asks for information for a calendar year. BRES asks about employment at a point in time within the year.
The two surveys also have different estimation methodologies, data validation and quality assurance and publication timetables. These differences mean that care should be taken with interpretation when using the employment data together with the ABS data at the more detailed industry levels.
7.3 Year-on-year comparison issues
The sample design for the employment data survey has undergone a number of amendments over the years, the most significant of which was the implementation of the BRES survey to replace ABI/1 in August 2009. Therefore, users should be aware that there are methodological break points at 2005, 2008 and 2009 for the employment information, making comparisons across these years more difficult.
Due to requests from employment data users in national accounts for a "common base year", ABI/1 data for 2008 (collected using an ABI/1 questionnaire) were processed using the new BRES results system, which had been improved by using a very different methodology from the ABI/1 results system. This means that data for 2008 are available on two approaches for the transitional year. This makes comparisons of employment measures before and after the break more feasible, however, as it is not possible to implement all the changes that occurred in moving from ABI/1 to BRES to the transitional year (namely recollecting data using the new questionnaire), caution should be taken when comparing employment measures across these years.
Back to table of contents8. The effect of different reporting periods on calendar year estimates
Respondents to the Annual Business Survey (ABS) are required to return data for a number of financial variables, ideally for the most recent calendar year – that is, for the period January to December. However, to reduce the burden on survey respondents, they are given the option to return data covering a business year ending on any date in a specified range. For example, for a particular survey year, the range for acceptable business year-ends was between 6 April and 5 April. As a result, the returns for that year are for a mixture of 15 different 12-month reference periods (see Figure 7).
Figure 7: Distribution of respondents to the Annual Business Survey by end reporting month
UK
Source: Annual Business Survey
Download this chart Figure 7: Distribution of respondents to the Annual Business Survey by end reporting month
Image .csv .xlsCurrently, no adjustment is made for the differing reporting periods; however, it is possible that, particularly if the economy is undergoing a period of rapid change such as during a recession, the different reporting periods could introduce some bias into the ABS published estimates.
Figure 8: Annual turnover for the UK manufacturing sector by response month
Source: ONS Monthly Business Survey
Download this chart Figure 8: Annual turnover for the UK manufacturing sector by response month
Image .csv .xlsFigure 8 illustrates, for example, how turnover in the manufacturing sector varies using rolling 12-monthly aggregations from the ONS Monthly Business Survey (MBS). In practice, not all ABS respondents in an industry would return covering the same period (Figure 7 shows that the majority report an annual period ending in December or March), so the impact of the variation in reporting periods on ABS estimates is likely to be small.
Back to table of contents9. Comparability of ABS estimates with other statistics
9.1 Comparison of ABS approximate GVA and national accounts GVA
This section provides a brief overview of the differences between measures of value added from the Annual Business Survey (ABS) and the national accounts. A more detailed explanation of the differences is available in A comparison between ABS and National Accounts measures of value added, published in April 2014.
The ABS publishes an approximate measure of gross value added at basic prices (aGVA). Gross value added (GVA) at basic prices is output at basic prices minus intermediate consumption at purchaser prices. The basic price is the amount receivable by the producer from the purchaser for a unit of a good or service minus any tax payable plus any subsidy receivable on that unit.
There are differences between the ABS approximate measure of GVA and the measure published by national accounts. National accounts carry out coverage adjustments, conceptual adjustments and coherence adjustments. The national accounts estimate of GVA uses input from a number of sources and covers the whole UK economy, whereas ABS does not include some parts of the agriculture and financial activities sectors, or public administration and defence.
ABS total aGVA is around two-thirds of the national accounts whole economy GVA because of these differences. Real (inflation-adjusted) estimates of national and regional GVA are published in the national accounts and regional accounts respectively. However, national and regional estimates of aGVA from the ABS are not adjusted for inflation.
Calculation of approximate GVA in the ABS
Approximate GVA is calculated as follows:
aGVA = output at basic prices – intermediate consumption
= total turnover
+ movement in total stocks
+ work of a capital nature carried out by own staff
+ value of insurance claims received
+ other subsidies received
+ amounts paid in business rates
+ amounts paid in Vehicle Excise Duty
- total purchases
- amounts received through the Work Programme
- total net taxes (note: for service industries, this is total taxes, not total net taxes)
Total turnover, movement in total stocks and total purchases are the variables published in the ABS statistical releases. Other variables are available on request by emailing abs@ons.gov.uk.
National accounts calculation of GVA
Estimates of turnover and purchases from the ABS are used to produce estimates of output and intermediate consumption (and therefore GVA) in the national accounts. The process of converting ABS estimates to national accounts estimates consists of a number of adjustments. These can summarised as:
removal of non-market activity included in the ABS coverage
adjustment to align with estimates of net taxes on production used in the national accounts
adjustment to align with estimates of inventories (finished goods, stocks of materials, storage and fuels, and work in progress) used in the national accounts
coverage adjustments
conceptual adjustments
addition of own-use and non-market output using data from other sources
coherence (balancing) adjustments
Although ABS data are used in the production of output and intermediate consumption, many other sources (including surveys and administrative sources) are also used to produce national accounts estimates. These include sources of data on taxation and inventories (which are preferred to the ABS as they are used consistently throughout all parts of the national accounts), as well as own-use output and non-market output (as these activities are only partially covered by the ABS).
There are differences between the two measures of gross value added in terms of coverage. For example, GVA covers the whole of the UK economy while aGVA covers the UK non-financial business economy, a subset of the whole economy that excludes large parts of agriculture, all of public administration and defence, publicly-provided healthcare and education, and the financial sector.
There are conceptual differences between the two measures of gross value added. For example, some production activities such as illegal smuggling of goods must be included in the national accounts but are outside the scope of the ABS.
There are three approaches to measuring gross domestic product (GDP); one based on production activity, one based on expenditure, and one based on income. In theory, the three approaches should produce the same estimate of GDP. However, in practice this is never the case because the three approaches make use of different data sources, each with their own definitions and limitations.
The three different estimates are therefore reconciled in a process known as supply and use balancing. The balancing process is informed by a variety of data sources and results in adjustments to estimates of output and intermediate consumption. For many industries, the balancing adjustment is the greatest source of difference between estimates from the ABS and the national accounts.
Table 14 shows aGVA as a percentage of GVA for each section of the UK Standard Industrial Classification 2007: SIC 2007 between 2012 and 2016. The aGVA data are taken from the Annual Business Survey, 2016 revised results, while the GVA data are taken from UK National Accounts, The Blue Book: 2018. Sections not covered by the ABS (financial and insurance activities, public administration and defence and compulsory social security, and activities of households of employers and activities of households for own use) have been excluded.
aGVA is substantially lower than GVA for sections L, A, P and Q. The first of these is due to the way activity in the real estate industry is measured in the national accounts (known as the imputed rent approach), while the other three reflect the partial coverage of the ABS for these sections. aGVA is consistently higher than GVA for a number of sections, most notably sections D, G, M and N.
Table 14: Approximate gross value added as a percentage of gross value added by Standard Industrial Classification 2007 section, UK, 2012 to 2016
| % | ||||||
| Section | 2012 | 2013 | 2014 | 2015 | 2016 | |
|---|---|---|---|---|---|---|
| A | Agriculture, forestry and fishing1 | 14 | 16 | 16 | 17 | 19 |
| B | Mining and quarrying | 87 | 80 | 73 | 69 | 64 |
| C | Manufacturing | 101 | 98 | 95 | 93 | 94 |
| D | Electricity, gas, steam and air conditioning supply | 124 | 100 | 97 | 85 | 85 |
| E | Water supply; sewerage, waste management and remediation activities | 95 | 96 | 113 | 116 | 113 |
| F | Construction | 85 | 85 | 87 | 90 | 92 |
| G | Wholesale and retail trade; repair of motor vehicles and motorcycles | 90 | 95 | 102 | 107 | 110 |
| H | Transportation and storage | 108 | 105 | 103 | 105 | 106 |
| I | Accommodation and food service activities | 92 | 86 | 91 | 92 | 91 |
| J | Information and communication | 99 | 100 | 108 | 107 | 110 |
| L | Real estate activities | 17 | 18 | 17 | 18 | 18 |
| M | Professional, scientific and technical activities | 109 | 114 | 117 | 119 | 121 |
| N | Administrative and support service activities | 125 | 133 | 142 | 142 | 144 |
| P | Education1 | 14 | 17 | 19 | 21 | 22 |
| Q | Human health and social work activities1 | 23 | 25 | 25 | 27 | 26 |
| R | Arts, entertainment and recreation | 72 | 97 | 104 | 102 | 83 |
| S | Other service activities | 44 | 46 | 49 | 49 | 49 |
| Total | 62 | 64 | 66 | 68 | 68 | |
| Source: Office for National Statistics | ||||||
| Note: | ||||||
| 1. Only partially covered by the ABS. | ||||||
Download this table Table 14: Approximate gross value added as a percentage of gross value added by Standard Industrial Classification 2007 section, UK, 2012 to 2016
.xls (38.4 kB)9.2 Comparison of Northern Ireland and ONS regional estimates
The Northern Ireland Statistics and Research Agency (NISRA), rather than Office for National Statistics (ONS), conduct the ABS in Northern Ireland. The survey process in Northern Ireland is similar but not exactly the same as that for Great Britain. For example, NISRA despatch questionnaires in March, after ONS despatch to businesses in Great Britain in January or February. ONS receive reporting unit and local unit level data for businesses sampled by NISRA in August and January of each survey year. These Northern Ireland reporting unit data are then processed together with the Great Britain data collected by ABS to produce estimates for the whole of the UK at various industry aggregations, as well as producing regional estimates.
NISRA also process the data to produce their own estimates for Northern Ireland. These differ from the ONS estimates for Northern Ireland for a number of reasons, which are detailed in this section.
Calculation of the a-weights
Since 2015, the ONS National and Regional Results Systems use the a-weights (design weights) calculated by NISRA to produce Northern Ireland estimates. Prior to this, however, the ONS Results System computed the a-weights (design weights) for Northern Ireland data using the sample design for Great Britain, which were quite different from those computed in the NISRA system.
Calculation of the g-weights
The ONS National Results System computes two sets of g-weights: one based on Inter-Departmental Business Register (IDBR) turnover and another based on IDBR employment. The latter is used for employment costs, whereas the former is used for all the other variables. The Regional System computes g-weights based on local unit employment. In the Northern Ireland methodology, IDBR employment is used for all variables in the calibration in their national system. In their regional system, the g-weights are computed with respect to local unit IDBR employment but using a different calibration method to that used in the ONS regional system.
Regional apportionment
ONS collects all ABS data at reporting unit level; the regional system apportions reporting unit returns between local units using factors obtained from multiple regression models. NISRA collects turnover data at local unit level, but does not use these data in their apportionment; their current apportionment is based on the median of per head returns. When Northern Ireland data are processed in the ONS system, new apportioned local unit values, based on the ONS methodology, are obtained and used to produce estimates. Also, ONS and NISRA use different methods to deal with local units operating in industries that are out of scope.
NISRA does not collect data for all the variables included in the Great Britain questionnaire; in the ONS system, values are derived for the missing variables using a model and these values contribute towards the estimation of derived variables.
See Section 5.8 of this technical report for more information on ONS regional methodology. NISRA and ONS are working closely together to better understand the impact of the different methods and where necessary, will analyse ways to better align the results.
9.3 Comparison with other business statistics
ONS and other government departments publish a variety of business statistics. Although the same variable, for example, turnover, may be published in different publications, estimates of this variable derived from different surveys will not be exactly the same. The main reasons for these differences are that the estimates will be based on:
different samples and sample sizes
data collected for different time periods
different definitions of variables (for example, point-in-time employment, or annual average employment)
sample selection occurring at different points in time
The reason for producing different estimates of the same variable is that, to fully understand the UK economy, monthly indicators of economic activity are required in addition to detailed breakdowns by, for example, industry, geography and size of business.
Detailed breakdowns require detailed responses from a large number of businesses (73,000 for the ABS). It is not possible to collect detailed data from this number of businesses on a monthly basis, because that would place an unacceptable level of burden on respondents, and would require huge resource to process the data. Therefore, ONS publishes annual, detailed, structural business statistics (for example, ABS) as well as more timely short-term indicators (for example, monthly retail sales). The main characteristics of the two approaches are presented in the next section. These should be taken into consideration when choosing which set of estimates to use for a specific purpose.
Structural compared with short-term business statistics
Structural business statistics (annual)
These measure the structure, content and performance of the business economy.
Data are collected and published annually.
They provide a snapshot of activity for a fixed reference year.
Detailed breakdowns by, for example, industry, geography and business size can be made.
The estimates often represent absolute amounts or monetary values.
Short-term indicators (monthly or quarterly)
These are early indicators of economic activity.
Data are generally collected and published monthly or quarterly.
The estimates represent time series, which measure, for example, month-on-month changes to the indicators.
The smaller sample sizes mean that detailed breakdowns are not possible.
The estimates do not generally represent absolute amounts or monetary values.
Finding the data you need
To help users find out what official business statistics are available, and to choose the right data for their needs, the Government Statistical Service (GSS) have published an interactive user guide for business statistics. By selecting the relevant topics of interest, the tool will pinpoint publications that should be of interest, offer guidance on the right statistic to use, and provide links to the relevant statistical releases.
The interactive guide covers both structural and short-term business statistics and includes measures of turnover and other financial transaction variables, economic growth and productivity. The statistical releases included in the guide, and links to other useful releases, can be found on the guide webpage.
International comparisons
International comparisons of structural business statistics are available from Eurostat (for the European Union) and the Organisation for Economic Co-operation and Development (OECD):
Eurostat: analysis of the European business economy
OECD: follow the link to the structural analysis database, under the industry and services theme
10. Acknowledgements
We thank all staff at Office for National Statistics who contributed to this report, either as an author, editor or advisor. Thanks, are also extended to staff from the Department for Business, Energy and Industrial Strategy and the Northern Ireland Statistics and Research Agency, who donated their time to provide invaluable feedback to us.
Back to table of contents11. Annex A: Users and uses of Annual Business Survey data
This section details the users and example uses of the Annual Business Survey (ABS) data.
Business advisors and consultancy
Example uses: Understanding trends in industry sectors and businesses in Scotland in comparison to Great Britain and the UK; sizing IT expenditure; number of enterprises and outlets at a detailed industry level; GVA per person employed by sector.
Department for Business, Energy and Industrial Strategy (BEIS)
Example uses: To compare efficiency of businesses who apply for grants; if problems occur within a particular industry; when new government interest arises within a particular sector; to distinguish bought-in goods from own production; Regional Economic Performance Indicators Publication.
Department for Digital, Culture, Media and Sport (DCMS)
Example uses: To estimate gross value added (GVA) within the DCMS Creative Industries Economic Estimates; to define the Creative Industries at the five-digit Standard Industrial Classification 2007: SIC 2007 level taking relevant SIC codes across the whole economy and aggregating into 13 DCMS Creative Sectors; to estimate the contribution of the Creative Industries to the UK business economy.
Department for Environment, Food and Rural Affairs (Defra)
Example uses: Used to select a sample of businesses in particular industrial sectors; regularly release anonymised micro-data from the survey about business spending to researchers.
Department for International Trade (DIT)
Example uses: Assessing the impact of importers and exporters in UK Industries.
Department for Work and Pensions (DWP)
Example uses: To measure the impact of 2010 Pensions legislation on wages, costs, profits and investment; to measure the way businesses change strategies to cover the new legislation, such as whether they absorb the costs or pass on costs to the customer; to analyse the traditionally low pension participation businesses.
Eurostat
Example uses: To meet the Structural Business Statistics Regulation (SBSR) requirements for annual structural statistics used to inform and monitor European Union policy; contribution to articles on SBS.
Food and drink sector
Used for estimating economic performance by region.
Her Majesty’s Revenue and Customs (HMRC)
Used for making comparisons on trade estimates.
Local government
Used for economic research, planning purposes, lobbying and economic strategy development.
Marketing and event organisation
Used for market sizing, demographic mapping, market segmentation and investment planning.
National and regional accounts
Example uses: The production of current and constant price supply use tables, which show the sales and purchases relationships between consumers and producers by industry; estimation of GVA on a regional basis.
Northern Ireland Statistics and Research Agency (NISRA)
Example uses: GVA per head compared with other areas of the UK; tracking performance of the NI economy; calculating the cost of doing business in Northern Ireland.
Retail sector
Used for assessing the market conditions.
Scottish Government
Example uses: Scottish Annual Business Statistics; Scottish Government policy and ABS data used in Scottish input-output tables, which in turn contributes to calculation of Scottish GVA weights.
Universities, research and think tanks
Used for research on the concentration profitability relationship in British manufacturing industries and setting up quota structures for business-to-business research.
Welsh Government
Data influence Welsh Government policy; and are used in the calculation of Welsh GVA.
Back to table of contents12. Annex B: List of Annual Business Survey questionnaire types
Table 15: List of Annual Business Survey questionnaire types
| Title of questionnaire | |
|---|---|
| Accountancy - Long | Market research - Long |
| Advertising - Long | Mineral Oil - Long |
| Animal Husbandry and Hunting - Long | Motor Trades - Long |
| Architecture - Long | Motor Trades - Short |
| Betting and Gaming - Long | Non-Market Organisations - Long |
| Catering - Long | Non-Market Organisations - Short |
| Catering - Short | Postal Activities - Long |
| Commission Industry - Long | Postal Activities - Short |
| Commission Industry - Short | Production Standard - Long |
| Computer Industry - Long | Production Standard - Short |
| Computer Industry - Short | Property - Long |
| Computer Services - Long | Property - Short |
| Construction - Long | Retail - Long |
| Construction - Short | Retail - Short |
| Duty - Long | Services Standard - Long |
| Duty - Short | Services Standard - Short |
| Employment Agencies - Long | Shipbuilding - Long |
| Engineering - Long | Sports Activities/Clubs - Long |
| Fishing - Long | Technical testing - Long |
| Forestry - Long | Transport - Long |
| Gas and Electricity - Long | Transport - Short |
| Insurance Organisations - Long | Water - Long |
| Legal - Long | Wholesale - Long |
| Management consultancy - Long | Wholesale - Short |
| Source: Office for National Statistics | |
Download this table Table 15: List of Annual Business Survey questionnaire types
.xls (37.4 kB)13. Annex C: Additions and removals of Annual Business Survey questionnaires
Table 16: Additions of Annual Business Survey questionnaires, UK, 2006 to 2016
| Title of questionnaire | Survey year added | Reason for addition | ||
|---|---|---|---|---|
| Advertising | 2008 | Required by Eurostat as part of the SBS Regulation. This is as part of Annex VIII - Business Services. | ||
| Employment agencies | 2008 | |||
| Legal | 2008 | |||
| Accountancy | 2008 | |||
| Management consultancy | 2008 | |||
| Computer Services | 2008 | |||
| Market research | 2008 | Required by Eurostat as part of the SBS Regulation. This is as part of Annex VIII - Business Services. Added in 2008, but first asked in 2009 under the regulation. | ||
| Architecture | 2008 | |||
| Engineering | 2008 | |||
| Technical testing | 2008 | |||
| Catering Long | 2011 | Added as part of the work Data Collection Methodology (DCM) have undertaken in trying to improve questionnaires. | ||
| Catering Short | 2011 | |||
| Standard Long | 2011 | |||
| Standard Short | 2011 | |||
| Sports activities and clubs | 2014 | Required by Eurostat as part of the European System of Accounts 2010: ESA 2010 regulation. | ||
| Source: Office for National Statistics | ||||
Download this table Table 16: Additions of Annual Business Survey questionnaires, UK, 2006 to 2016
.xls (37.9 kB)
Table 17: Removals of Annual Business Survey questionnaires, UK, 2006 to 2016
| Title of questionnaire | Survey year removed | Reason for removal | ||
|---|---|---|---|---|
| Entertainment industry – Long | 2006 | No longer required. | ||
| Entertainment industry – Short | 2006 | |||
| Finance organisations – Long | 2008 | As part of the SBS Regulation ABS were no longer required to collect these SIC's. Therefore it made sense to remove these questionnaires. | ||
| Finance organisations – Short | 2008 | |||
| Insurance – Short | 2008 | For the Insurance SIC's ABS were required to only collect the common module variables (Annex I of the SBSR). | ||
| Gas and electricity incl. PI | 2007 | As ABS no longer collect the PI (dropped in 2005) there was no longer a requirement to have a questionnaire. (The 106 questionnaire would suffice for ABS needs). | ||
| Utilities | 2009 | There used to be a composite SIC under the SIC03 - 39000 which collected Utilities. When this was no longer needed under the SIC07 it was felt that this questionnaire type could be removed (The 106 would collect Gas and Electricity companies and the 109 Water Companies). | ||
| Source: Office for National Statistics | ||||
Download this table Table 17: Removals of Annual Business Survey questionnaires, UK, 2006 to 2016
.xls (37.4 kB)14. Annex D: Nomenclature of Units for Territorial Statistics (NUTS)
The Nomenclature of Units for Territorial Statistics (NUTS) is a hierarchical classification of geographical units that provides a breakdown of the European Union's territory for the purposes of producing comparable regional statistics. There are various levels of NUTS from UK countries and regions.
For example, in the NUTS classification, Wales is a level-one NUTS region, coded "UKL", which is subdivided as shown in Table 18.
Table 18: Wales and its subdivisions according to the Nomenclature of Units for Territorial Statistics (NUTS) hierarchy
| NUTS 1 | NUTS 1 code | NUTS 2 | NUTS 2 code | NUTS 3 | NUTS 3 code |
|---|---|---|---|---|---|
| Wales | UKL | West Wales and the Valleys | UKL1 | Isle of Anglesey | UKL11 |
| Gwynedd | UKL12 | ||||
| Conwy and Denbighshire | UKL13 | ||||
| South West Wales (Ceredigion, Carmarthenshire, Pembrokeshire) | UKL14 | ||||
| Central Valleys (Merthyr Tydfil, Rhondda Cynon Taff) | UKL15 | ||||
| Gwent Valleys (Blaenau Gwent, Caerphilly, Torfaen) | UKL16 | ||||
| Bridgend and Neath Port Talbot | UKL17 | ||||
| Swansea | UKL18 | ||||
| East Wales | UKL2 | Monmouthshire and Newport | UKL21 | ||
| Cardiff and Vale of Glamorgan | UKL22 | ||||
| Flintshire and Wrexham | UKL23 | ||||
| Powys | UKL24 | ||||
| Source: Office for National Statistics | |||||
Download this table Table 18: Wales and its subdivisions according to the Nomenclature of Units for Territorial Statistics (NUTS) hierarchy
.xls (37.4 kB)
Figure 9: Wales and its subdivisions according to the Nomenclature of Units for Territorial Statistics (NUTS) hierarchy
{kind=link}